PDF文本提取有什么难的?
人们普遍认为,从PDF文档中提取文本应该不会太难。毕竟,文本就在我们眼前,人类一直在成功地消费PDF内容。为什么自动提取文本数据会有困难?
事实证明,由于大量的边缘情况和不正确的假设,处理人名是多么困难,处理PDF是困难的,因为PDF格式赋予了极大的灵活性。
主要问题是,PDF从未真正设计为数据输入格式,而是设计为一种输出格式,可对生成的文档进行细粒度控制。
PDF格式的核心是由描述如何在页面上绘制的指令流组成。具体地说,文本数据不是以段落形式存储的,甚至不是以单词形式存储的,而是以字符的形式存储在页面上的特定位置。因此,当文本或Word文档转换为PDF时,大多数内容语义都会丢失-所有隐含的文本结构都会转换为页面上漂浮的几乎无定形的字符。
作为构建FilingDB的一部分,我们已经从数万个PDF文档中提取了文本数据。在这个过程中,我们看到关于PDF文件结构的每一个假设都被证明是不正确的。我们的任务尤其困难,因为我们必须处理来自不同来源的PDF文档,这些文档具有截然不同的样式、排版和演示方式选择。
下面的列表记录了PDF文件使提取文本内容变得困难(甚至不可能)的一些方式。
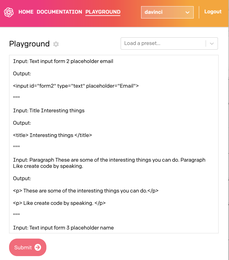
您可能遇到过拒绝复制其文本内容的PDF文件。例如,以下是SumatraPDF在尝试从受复制保护的文档复制文本时显示的内容。
有趣的是,文本已经可见,但是PDF查看器拒绝用突出显示的文本填充剪贴板。
实现这一点的方式是拥有几个“访问权限”标志,其中一个标志控制是否允许复制内容。重要的是要记住,这一限制不是由PDF文件强制执行的-实际的PDF内容不受影响,这取决于PDF渲染器是否遵守这一标志。
不用说,这并不能真正防止从PDF中提取文本,因为任何相当复杂的PDF处理库都允许用户切换标志或忽略它们。
PDF文件包含的文本数据多于页面上实际显示的文本数据的情况并不少见。下面是雀巢2010年度报告中的这一页。
与此页面相关联的文本比看上去要多。特别是,可以在与此页面关联的内容数据中找到以下内容:
“KitKat在2010年庆祝了它成立75周年,但它仍然年轻并紧跟潮流,在Facebook上拥有超过250万粉丝。它销往70多个国家,在中东、印度和俄罗斯等发达国家和新兴市场增长良好。日本是它的第二大市场。“。
该文本实际上位于页面边界框之外,因此大多数PDF查看器不会显示它,但是数据在那里,并且在以编程方式提取文本时会出现。
由于在排版过程中最后一刻决定删除或替换文本,偶尔会发生这种情况。
PDF有时会在页面上引入非常小的或隐藏的文本。例如,以下是雀巢2012年度报告的一页。
这样做有时是为了便于访问,类似于在HTML中使用alt属性的方式。
有时PDF在单词中的字母之间包含额外的空格。这很可能是出于字距调整的目的。(“字距调整”是指在排版过程中调整字符之间的距离的过程)。
“你知道我是谁吗?”
重构原文是一个普遍难以解决的问题。我们最成功的方法是应用OCR技术。
至少可以说,PDF字体处理很复杂。要了解PDF文件如何存储文本数据,我们必须首先了解字形、字形名称和字体。
字形是描述如何绘制符号或字符的一组指令。
字形名称是与该字形关联的名称。例如,“商标”代表“™”字形,“a”代表“a”字形。
字体是具有关联字形名称的字形列表。例如,大多数字体都有一种大多数人会将其识别为字母“a”的字形,不同的字体显示了绘制该字母的不同方式。
在PDF中,字符以数字形式存储,称为“代码点”。要决定在屏幕上绘制什么,渲染器必须:
例如,PDF文档可以包含码点116,码点116映射到字形名称“t”,而字形名称“t”又映射到描述如何在屏幕上绘制“t”的字形。
现在,大多数PDF文件使用标准的码点编码。码点编码是为码点本身分配意义的一组规则。例如:
ASCII和UNICODE都使用码点116来表示字母“t”。
UNICODE将代码点9786映射到“白色笑脸”,呈现为☺,而ASCII码没有在该代码点定义。
但是,PDF文档偶尔会将其自己的自定义编码与自定义字体一起使用。这可能看起来很奇怪,但是文档可以使用代码点1来表示字母“t”。它将码点1映射到字形名称“C1”,该字形名称将映射到描述如何绘制字母“t”的字形。
虽然对人类来说,最终结果看起来是一样的,但机器会被它看到的代码点搞糊涂。如果代码点不遵循标准编码,那么实际上不可能通过编程知道代码点1、2和3代表什么。
另一个是子字体的使用。大多数字体包含大量码点的字形,而PDF可能只使用其中的一个子集。为了节省空间,PDF创建者可以去除所有不需要的字形,并创建很可能使用非标准编码的紧凑子字体。
一种解决方法是从文档中提取字体字形,通过OCR软件运行它们,然后构建从字体字形到Unicode的映射。这然后允许您将特定于字体的编码转换为Unicode编码,例如:代码点1被映射到名称“C1”,基于字形,该名称应该是“t”,即Unicode代码点116。
您刚刚生成的从1到116的编码映射在PDF标准中称为ToUnicode映射。PDF文档可以提供它们自己的ToUnicode映射,但它是可选的,许多文档不提供。
从PDF文件中杂乱无章的字符汤中重建段落甚至单词是一项艰巨的任务。
PDF文档提供页面上的字符列表,用户可以自行识别单词和段落。人类天生就能做到这一点,因为阅读是一项广为流传的技能。
通常的方法是具有分组或聚类算法,该算法比较字母大小、位置和对齐,以便确定什么是单词/段落。
朴素的实现很容易具有大于O(n²)的复杂性,从而导致繁忙页面的处理时间较长。
首先,有时没有正确的答案。虽然采用传统单栏排版的文档阅读顺序自然,但采用更具冒险风格的布局的文档则颇具挑战性。例如,不清楚下面的插图应该出现在文章之前、之后还是在文章旁边:
其次,即使答案对人类来说是显而易见的,确定稳健的段落顺序也是一个非常困难的问题,甚至可能是人工智能的难题。这可能听起来像是一种极端的说法,但是在某些情况下,只有通过理解文本内容才能确定正确的段落顺序。
在西方世界,一个合理的假设是阅读是从左到右,从上到下进行的。所以我们在不看内容的情况下,最多只能把答案减少到两个选项:A、B、C、D和A、C、B、D。
通过看内容,了解它在说什么,知道蔬菜在切之前是洗的,我们就可以确定A、C、B、D是正确的顺序。从算法上确定这一点是一个困难的问题。
也就是说,一种“大多数情况下都有效”的方法是依赖于文本存储在PDF文档中的顺序。这通常与创建时插入文本的顺序相对应,对于包含多个段落的大块文本,它们往往会反映作者预期的顺序。
部分(或全部)PDF内容实际上是扫描的情况并不少见。在这些情况下,没有可以直接提取的文本数据,所以我们不得不求助于OCR技术。
例如,Yell 2011年度报告仅提供文档扫描:
虽然OCR可能有助于解决上面显示的一些问题,但它也有自己的一组缺点。
处理时间长:在PDF扫描上运行OCR通常比直接从PDF提取文本要长至少一个数量级。
非标准字符和字形的困难:OCR算法很难处理新字符,如笑脸、星形/圆圈/正方形(用于项目符号列表)、上标、复杂的数学符号等。
没有文本顺序提示:大多数情况下,按照正确的阅读顺序对从PDF文档中提取的文本进行排序会更容易,因为插入顺序会提示您使用正确的阅读顺序。从图像中提取文本不会提供这样的提示。
我们到目前为止还没有提到的一个方面是,确认提取的文本是正确的还是预期的是多么困难。我们发现最有用的方法是有一套广泛的测试,既检查基本的指标(例如,文本长度、页面长度、空格与单词的比率),也检查更复杂的指标(例如,英语单词与无法识别的单词的百分比、数字的百分比),并检查可疑或意外字符等危险信号。
那么,当涉及到从PDF中提取文本时,我们的建议是什么呢?最重要的是,确保没有更好的替代数据源可用。
如果您感兴趣的数据只是PDF格式,那么重要的是要意识到这是一个看似简单的问题,100%准确的解决方案很可能是不可能的。