松弛的追踪:因果关系图中的思考
“为什么这么慢?”是像Slake这样复杂的分布式系统中最难调试的问题。要诊断具有超过十万个用户的低速加载通道,我们需要查看客户端指标、服务器端指标和日志。可能是客户端问题:网络连接或硬件速度慢。另一方面,这可能是服务器端的问题:请求执行错误或代码中的边缘情况。当我们必须跨客户端设备、网络设备、后端服务和数据库手动关联单个请求的所有日志和指标时,对这些问题进行分类和修复是一个乏味的过程。
Sack使用Prometheus(指标)和Elasticsearch/Presto(日志查询)等工具来提供对这些问题的可见性。虽然指标提供了请求性能的聚合视图,但我们没有关于特定请求速度慢的原因的细粒度信息。我们的日志确实包含跟踪如何处理特定请求所需的粒度上下文,但它们不能提供有关该事件之前或之后发生的其他上下文。
分布式跟踪是跨服务将请求组合在一起的常用解决方案。然而,我们以前的跟踪经验揭示了两个限制,这使我们在采用现有解决方案时犹豫不决。正如Cindy Sridharan在这篇文章中记录的那样,使用现有的跟踪工具并通过跟踪UI使用跟踪可能无法证明构建解决方案的投资是合理的。此外,当前的跟踪框架主要是为后端服务设计的,我们发现它们不适合我们的客户端应用程序和shell脚本。
除了在跟踪UI中查看跨度之外,我们还希望通过使用SQL查询运行即席分析来从跟踪数据中获得更多信息。正如Dan Luu在这篇文章中记录的那样,这种洞察力反映了Twitter在查询原始跟踪数据以获得洞察力方面的经验。
为了解决这些限制并方便地查询原始跟踪数据,我们将Slake的跟踪建模为因果图,这是一种名为span Event的新数据结构的有向非循环图。这篇文章是我们讨论我们在Slake的跟踪系统的动机和体系结构的系列文章中的第一篇。
要使用日志和度量对提高的错误率或性能倒退进行分类,我们必须在心理上重建作为请求的一部分发生的事件链。这需要来自不同服务链的相关指标和日志。一旦我们有了一个有代表性的请求及其事件链,问题的原因通常是显而易见的。
分布式跟踪自动执行上述手动关联,跨多个服务跟踪请求以创建相关日志。典型的分布式跟踪设置涉及以下组件:
检测:通常使用开放源码跟踪库检测应用程序。它由3个组件组成:采样器、跟踪上下文传播库和SPAN报告器。采样器对传入的请求进行采样,以查看是否应该选择该请求进行跟踪。跟踪上下文传播库负责跟踪请求,并跨进程中的线程(进程内)以及跨各种服务(进程间)传播跟踪上下文。SPAN报告器负责收集产生的跨度,并将它们报告给跟踪摄取管道或后端存储系统。
接收:跟踪接收管道捕获应用程序发出的跨度,根据需要执行任何附加采样(尾部采样),并将跨度数据写入跟踪存储系统。
存储和可视化:跟踪存储组件将跟踪存储设定的天数,并允许搜索和可视化跟踪数据。轨迹最常见的可视化图层是瀑布视图。
Zipkin和Jaegar是遵循上述模型的两个最流行的开源跟踪项目。
我们发现传统的分布式跟踪方法并不适合我们。从Dapper这样的系统开始,分布式跟踪社区传统上将跨系统传播的事件序列建模为分布式跟踪。轨迹中的每个段称为跨度。虽然作为因果相关事件序列(因果图)的跟踪的核心思想并不新鲜,但其核心思想常常被更高级别的API和内部范围格式所掩盖。我们的跟踪系统的目标是构建和操作一种称为因果图的简化形式的跟踪。在本节中,我们将讨论为什么我们需要明确指出因果关系图中的思考比痕迹中的思考更基本。
目前,像OpenTracing这样的跟踪API被设计用来跟踪用高级多线程语言编写的后端服务之间的请求-一个有明确开始和结束的操作。除了创建跨度并将其报告给跟踪后端的简单API之外,插装库还跟踪由应用程序内的各种线程和线程池处理的请求。
虽然当前的API对于它们的预期用例工作得很好,但在操作没有明确开始或结束的上下文中使用这些API可能会令人困惑,甚至是不可能的。要跟踪移动应用程序或JavaScript框架(其事件循环调用应用程序代码(控制反转)),我们需要在现有API中采用复杂的解决方法,这些API通常会破坏这些库提供的抽象。
当事务上下文不包含在请求上下文中时,当前的跟踪API可能过于严格或不灵活。
从理论上讲,我们可以使用跟踪通过NPM或Maven等构建工具、Jenkins中的CI/CD流或复杂的shell脚本执行来表示依赖图。虽然这些进程不遵循与GRPC应用程序相同的执行模型,但它们的大部分执行可以表示为跟踪,并且可以从跟踪分析工具中获益。此外,我们还发现,在这些用例中,可能有多个请求流(通过Kafka、Goroutine、流系统的生产者-消费者模式)同时发生,或者我们可能希望跨多个请求流跟踪单个事件。在任何一种情况下,使用单个跟踪程序来执行整个应用程序都可能是一个限制因素。
对于没有明确的请求概念的用例,轻量级API更可取。虽然下面这样更简单的API将进程内/进程间上下文传播的负担推给了应用程序开发人员,但它更易于使用,并且允许更渐进地添加对非传统应用程序的跟踪。
原始跨度是跟踪系统中的内部实现细节。这些跨度不是由用户直接生产或消费的。
每个跟踪系统都有自己的SPAN格式(Zipkin的SPAN SARIFT模式,Jaegar的SPAN SARIFT模式)。因为它们不是被设计成供人类直接使用的,所以它们通常被设计为内部格式,并且在深度嵌套的结构中包含许多附加元数据。这些内部实现细节对用户是隐藏的,用户在创建时通过检测API与这些跨度交互,在消费时通过跟踪UI与这些跨度交互。
如果我们要直接从应用程序生成跨度,我们会让我们的开发人员暴露在几个令人困惑的字段中。例如:
Zipkin和Jaeger跨度都有注释/日志,用于声明在跨度持续时间内发生的零持续时间事件。然而,如果这些事件附加了持续时间,它们将被建模为子跨度。
Jaegar span没有用于存储服务名称的字段。跨区的服务名称在进程对象中定义。
Zipkin和Jaeger跨度上的trace_id都表示为2个64位整数,这是存储优化。
这些跨度是以网络为中心的。Zipkin在注释和BinaryAnnotation上都有一个端点作为字段,以捕获流程的网络信息。Jaegar跨度封装在进程结构中。
跟踪记录了非常丰富的因果和上下文数据。然而,考虑到其SPAN格式的复杂性,这些跟踪系统不允许我们以交互速度对原始SPAN数据运行复杂的分析。例如,我希望能够提出这样的问题:“我是否因为特定http端点上的数据库查询速度慢而错过了我的SLA?”即使跟踪包含这些信息,用户通常也必须编写复杂的Java程序来回答他们的问题,这需要花费数天的时间。如果没有一种简单的方式来提出强大的分析问题,用户只能满足于从跟踪视图中收集的洞察力。这极大地限制了利用跟踪数据进行分类的能力。
我们的经验与本文相符,因为跟踪系统的约束和限制通常不能证明在组织中实现跟踪的努力是合理的。即使实施了追踪系统,一旦最初的兴奋消退,它也会半途而废。因此,与容器、微服务、集中日志记录和服务网格等技术相比,跟踪在行业中的应用乏善可陈也就不足为奇了。
鉴于目前追踪系统的局限性和我们以往的经验,我们制定了以下目标,以使我们的努力取得成功:
我们的跟踪系统在我们的后端系统(例如:移动、桌面客户端和异步服务)之外应该是有用的。
简单的事情应该很容易。困难的事情应该是可能的。为非后端使用情形提供简单、轻量级的API。高级API,用于捕获以多种语言编写的后端服务内部和跨后端服务的复杂请求交互。
跟踪对于实时分类事件和性能倒退应该很有用。我们认为这将证明追踪系统的投资回报是合理的。
系统用户应该能够查询原始跨度数据,并对属于不同轨迹的跨度或轨迹内的跨度运行分析。
跟踪系统应该提供用于查询跟踪的可视化查询语言和直观的UI来可视化我们的跟踪和分析。
跟踪的核心思想是称为跨度的关联事件的有向无环图。但是,这通常包装在更高级别的跟踪API中,并通过跟踪UI公开。这种隐藏的结构使我们无法实现查询原始跟踪数据和使跟踪适合于各种用例的目标。
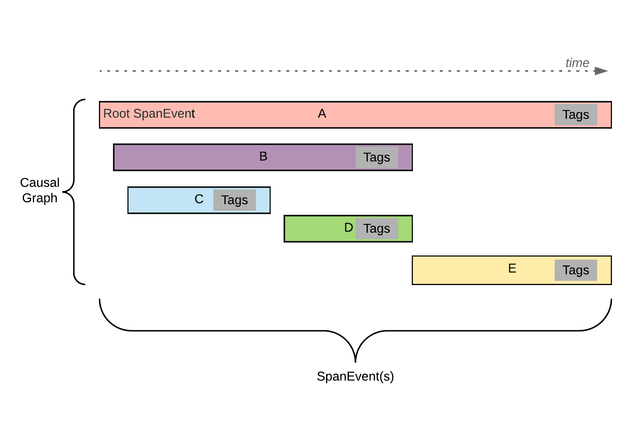
像踪迹一样,因果图是span Event的有向无环图。因果图和span Event捕获跟踪和范围的基本方面,旨在满足我们在上一节中定义的目标。下图显示了因果关系图的高级概述:
图1:示例因果关系图是span Events的图。在上图中,每个水平矩形表示一个跨区事件。因果关系图中没有父级的第一个span Event称为根。一个span Event可以是另一个span Event的子级。每个span Event可以有选择地附加标签。子span Event可以超出父span Event的持续时间。
Facebook的Canopy还定义了一个自定义事件格式来表示跨度和轨迹。我们认为因果关系图和span Event是该格式的发展,它消除了对其摄取管道的模型重建阶段的需要。
因果图是span Event对象的图。Span Event包含以下字段:
Trace id-string-表示跟踪的id(对于深度嵌套的跨区事件)。
在分布式跟踪系统中,我们将span Events视为比SPAN更低级别的对象,因为我们对其包含的数据没有任何限制。数据正确性由更高级别的跟踪API或用户应用程序保证。因此,span Event可以表示相关事件的任何图形。Span Event对于跟踪系统就像llvm IR对于编程语言一样。您可以直接生成原始的span Event,也可以使用更高级别的API来创建它们。
我们采用扁平结构,避免在span Event本身上嵌套很深的列表。像注释这样的嵌套列表表示为具有专用跨度类型标记的子跨度。这使得在查询时根据需要非常容易地过滤出注释,而不需要复杂的SQL查询。虽然这使得注释在网络上的效率略有降低,但我们认为生产和消费的简便性证明了这种权衡是合理的。
我们还在跨度上使用持续时间字段而不是结束时间,因此在使用它们时不必减去开始和结束时间字段。
我们允许持续时间为零且ID为空的跨度。根跨度可能与整个跟踪的持续时间匹配,也可能不匹配。我们还鼓励只有一个跨度的跟踪,因为它们可以在查询时与其他跨度事件连接。这还允许在不对父范围进行任何修改的情况下将更多的子范围逐渐添加到这些事件中。此外,这确保了在添加子范围时不需要更改我们在较旧数据上编写的查询。
我们不在范围内选择可选字段,而是选择带有预留键的标记,用于众所周知的字段和键入的值。这极大地简化了范围创建和查询。任何对机器使用有用的信息,比如对其他范围的引用,都被定义为标记或特定子范围。
生成SPAN事件:span Events可以通过几种方式生成。最简单的方法是从代码生成协议Buf或JSON对象,并使用类似createAndReportSpan的简单函数调用将其发布到我们的后端。通过调用cURL命令可以实现相同的功能,如下所示。这使得添加跟踪与在代码中添加日志语句或在shell脚本中调用附加命令一样简单。我们的移动应用程序和shell脚本经常使用这种方法。
Curl-X POST-H";X-SLACK-SES-ID:123455678";-d';[{";id";:";bW9ja19zcGFuX2lk";, ";parent_id";:";bW9ja19wYXJlbnRfaWQ=";, ";trace_id";:";bW9ja190cmFjZV9pZA==";, ";名称";:";披萨";, ";Start_timeamp_micros";:1565045962061019, ";Duration_micros";:2000, ";标签";:[ {";key";:";topping";,";v_type";:0,";v_str";:";xtra_Cheas";}, {";密钥";:";SERVICE_NAME";,";V_type";:0,";v_str";:";披萨时间";} ] }]';https://internal.slack.com/traces/v1/spans/json。
对于Hack和JavaScript应用程序,我们已经实现了与OpenTracing兼容的跟踪器,可以生成span Event格式的跨度。对于Go和Java应用程序,我们分别使用Jaegar Go和Zipkin Brave提供的令人惊叹的开源插件库。我们已经编写了适配器来将这些库生成的跨度转换为我们的span Event格式。
查询跨度:我们选择SQL作为跨度数据的查询语言,因为它使用广泛、灵活、易于入门,并且受到各种存储后端的支持。此外,对于不习惯SQL的用户,有几个众所周知的可视界面可以制定SQL查询。虽然冗长,但我们发现SQL非常适合表达跟踪数据的简单分析和复杂分析。
我们的跟踪系统的架构如下图所示。它由以下组件组成:
我们的Hack应用程序配备了与OpenTracing兼容的跟踪器。我们的移动和桌面客户端使用高级跟踪程序或低级跨区创建API跟踪它们的代码并发出span Event。这些生成的span Event作为JSON或Protobuf编码事件通过HTTP发送给Wallace。
Wallace是一个用Go编写的HTTP服务器应用程序,它独立于我们的基础设施的其余部分运行,因此即使Slake关闭,我们也可以捕获错误。华莱士验证它收到的SPAN数据,并通过Murron将这些事件转发给卡夫卡。Murron是我们的内部事件总线,它将日志、事件和指标从我们的应用程序路由到我们基础架构中的各种存储后端。
我们的内部Java和Go应用程序分别使用来自Zipkin和Jaegar的开放源码插装库。为了捕获这些应用程序的跨度,Wallace公开了两个项目的报告端点。这些端点称为跟踪适配器,它们将报告的跨度转换为我们的span Event格式,并将它们写入Wallace。
写入Kafka的跟踪数据使用lambda架构进行处理。Murron Consumer是一个内部Go应用程序,它从Kafka读取我们的span Events,并将它们发送到实时商店和我们的数据仓库。
实时存储几乎可以立即访问我们的跟踪数据,端到端延迟不到5秒。我们使用Honeycomb来可视化这些数据并运行简单的分析,它在使我们的跟踪对分类有用方面发挥了重要作用。
相比之下,我们的数据仓库落后2小时。这里我们使用的是Presto,它通过SQL支持更长时间范围内的复杂分析查询。我们的工程师用它来更好地了解长期趋势,并回答他们用蜂巢无法轻松解决的问题。
目前,我们的跟踪管道在堆栈中端到端地跟踪请求,从客户端到后端服务,再到存储层。我们还有几个新的跟踪应用程序,比如跟踪客户端中的websocket状态和监视Jenkins CI/CD管道执行。我们甚至跟踪了我们的构建依赖图,以了解我们的构建在哪里慢。
与Slake的其他服务一样,跟踪的采用遵循了Sigmoid曲线。我们的跟踪管道已经投入生产一年多了,我们跟踪来自客户的所有请求的1%。对于一些小批量服务,我们100%追溯。我们目前的管道每天处理约310M个跟踪,每天处理约8.5亿个跨度,每天产生约2TB的跟踪数据。
查询原始痕迹的能力开启了我们在Slake的服务和客户体验的一些非常强大的洞察力。跟踪已成为对Slake的性能问题进行分类和修复的主要方法之一。我们还利用跟踪数据成功地对生产事件进行分类,并估计部署或事件对最终用户的影响。
使用跟踪数据,我们还可以回答有关我们的应用程序的非常复杂的问题,这些问题在以前是不可能的,例如:
针对给定请求运行哪些异步任务?这些任务花了多长时间?
因果图模型和span Event格式允许我们将每个跨度表示为表中的单行。这种简单性使得查询跟踪数据变得容易,跟踪的价值主张也变得简单明了。因此,跟踪在整个组织中得到了迅速采用。相比之下,Twitter的跟踪数据被分成6个表,虽然效率可能更高,但会使查询变得更加困难。
为了针对向我们的CE团队报告的特定客户问题进行有针对性的调查,桌面客户端团队向我们的客户端添加了一个特殊的斜杠命令,该命令在接下来的两分钟内跟踪客户端上的每个请求。运行此命令后,我们将跟踪来自客户端的所有请求,而不对其进行采样。
我们的客户团队还开始使用span Events作为向后端报告客户端日志的通用事件格式。重用span Event格式帮助我们利用了相同的跟踪和日志实时接收管道。在两者之间使用相似的字段名也使得查询更加直观。
在生产中运行该系统一年后,我们可以自信地说,我们已经实现了我们的跟踪管道设定的所有目标。
将来,我们计划通过添加更强大的查询语言来查询跟踪数据,从而在这一成功的基础上再接再厉。
对于大型服务,我们目前抽样了1-2%的请求。我们希望提供一种方法来采样一组用户的所有请求(a。
.