使用Zygote-Train XOR开始使用Julia中的自动微分
嗨。这是一个关于构建一个非常简单的多层感知器来近似异或函数的教程,对于它的朋友来说称为XOR函数。这也可能是您对Julia编程语言的介绍,并且代表了我使用该语言的一些早期实验。Julia是为科学计算而开发的,多亏了即时编译,表面上看,它是一种速度更快的Python。该语言的一个有趣特性是,当您看到神经网络中密集层的数学定义时,如下所示:
𝑓(𝑥)=𝜎(𝜃𝑤𝑥+𝑏)f(X)=σ(θwx+b)。
由于Julia对Unicode字符的支持,您实际上可以编写看起来非常相似的代码。它不一定会节省您打字的时间(符号是通过输入Latex代码来输入的,例如,\sigma然后按Tab键),但它看起来确实很酷。以下是Julia中的完全合法代码:
σ(X)=1./(1.+exp.(-x))f(x,θ)=σ(x*θ[:w].+θ[:b])θ=dict(:w=>;Randn(32,2)/10,:b=>;Randn(1,2)/100)x=Randn(4,32)f(x,θ)。
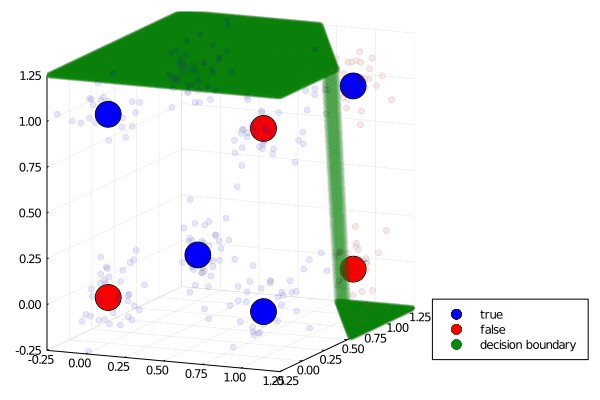
异或(XOR)函数是一个用简单的神经网络逼近的有吸引力的函数,既因为它的简单性,也因为它在人工智能研究历史上有些臭名昭著的地位。上世纪60年代,两位人工智能贵族的魔术师宣布,他们发现,输入到单个输出节点(弗兰克·罗森布拉特(Frank Rosenblatt)的感知器(Perceptron)或麦卡洛赫-皮茨(McCulloch-Pitts)神经元)的加权映射不能拟合XOR函数,这让前沿陷入了一段时期的混乱和黑暗。或者说传说是这样的。回过头来看,明斯基和佩珀特的一些正式论点似乎被认为是所有实际执行的象征。事实上,他们只证明了需要密集连接(即非局部权重)和多层才能正确识别奇偶校验谓词(XOR)。
#用直线分隔OR很容易,您的眼睛会自动挑选出答案1 x x 0 o x 0 1\x x\0 o\x\0 1#分隔XOR并非易事,您需要一条曲线才能做到这一点。1 x\o_\_|0 o\x|0 1。
从那时起,在为ML选择一种新语言时,编写MLP来解决XOR问题就成了一种传统。
我们将使用来自FlosML的自动区分包Zygote。如果您以前使用过Autograd或JAX,Zygote会觉得很熟悉,因为Zygote是一个真正的“软件2.0”精神的autodiff包。您可以区别于原生Julia代码,包括循环、流控制和递归。这可能有一些非常好的优点,例如,您可以通过物理模型来区分,以改进强化学习风格控制问题的学习。在我们的例子中,我们只针对几个矩阵乘法进行区分,如果您更喜欢以Jupyter笔记本的形式互动地欣赏本教程,请访问GiHub repo。
我们将使用Zygote自动给我们一个渐变来更新我们的NN参数。如果您习惯于在PyTorch中调用loss.backward()或者显式地编写您自己的向后传递,那么这看起来可能会有一些不同。合格特自动为我们执行向前和向后传球。不幸的是,这意味着我必须为训练度量和梯度调用单独的前向传递,但是当我找到避免冗余的前向传递调用的好方法时,我会在这里添加一个更新。
LR=1E1;x,y=GET_XOR(64,5);θ=初始化权重(5);旧权重=追加!(RESHAPE(θ[:wxh],SIZE(θ[:wxh])[1]*SIZE(θ[:wxh])[2]),RESHAPE(θ[:WHY],SIZE(θ[:Wxh])[1]*SIZE(θ[:Wxh])[2])dθ=渐变((θ。PLT=SISTTER(OLD_WEIGHTS,LABEL=";OLD_WEIGHTS";);θ[:wxh],θ[:Wxh]=θ[:wxh].-lr.*Dθ[1][:wxh],θ[:为什么].-lr.*dθ[1][:为什么]NEW_WEIGHT=APPEND!(RESHAPE(θ[:WXH],SIZE(θ[:WXH])[1]*SIZE(θ[:WXH])[2]),RESHAPE(θ[:WXH]),Size(θ[:为什么])[1]*Size(θ[:为什么])[2])散布!(NEW_WEIGHT,LABEL=";新权重(#34;)显示(PLT)。
现在开始吧。首先,我们将导入我们将使用的包。这是Zygote和其他几个,我们将用来绘制和计算统计数据。
我们需要训练数据和一些矩阵来充当神经权重,下面的函数将为我们生成这些权值。
Get_xor=函数(num_sample=512,dim_x=3)x=1*rand(num_sample,dim_x)。>;0.5 y=零(num_sample,1),ii=1:size(Y)[1]y[ii]=Reduce(xor,x[ii,:])end x=x+randn(num_sample,dim_x)/10 return x,y end init_weights=function(dim_in=2,dim_out=1,dim_hid=4)wxh=randn(dim_in,dim_hid)/8为什么=随机n。Wxh,:为什么=>;为什么)返回θ结束。
接下来的部分定义了我们将要训练的模型:一个有1个隐藏层且没有偏向的微型MLP。我们还需要设置一些帮助器函数来提供损失和其他训练指标(准确性)。要使用Zygote的自动区分功能,我们需要一个返回标量目标函数的函数。
F(x,θ)=σ(σ(x*θ[:wxh])*θ[:为什么])Get_Accuracy(y,Pred,BORLD=0.5)=Mean(y.==(Pred.>;边界))LOG_LOSS=函数(y,PRED)RETURN-(1/SIZE(Y)[1]).*SUM(y.*log.(PRED).+(1.0.-y).*log.(1.0.-PRED))END GET_LOSS=Function(x,θ,y,L2=6e-4)PRED=f(x,θ)LOSS=LOG_LOSS(y,PRED)损失=损失+L2*(SUM(abs.(θ[:wxh].^2))+SUM(abs(θ[:为什么].^2)退货损失结束。
Zygote的渐变函数顾名思义。我们需要给梯度一个函数来返回我们的目标函数(在本例中是log Lost),这就是为什么我们在前面做了一个显式的Get_Lost函数。我们将把结果存储在名为dθ的字典中,并通过梯度下降来更新我们的模型参数。下面的函数定义了我们的训练循环。
Train=Function(x,θ,y,max_step=1000,LR=1e-2,L2_reg=1e-4)DISP_EVERY=最大步数//100损耗=零(最大步数)acc=零(最大步数)对于步长=1:MAX_Steps PRED=f(x,θ)损耗=LOG_LOSS(y,PRED)损耗[步长]=损耗Acc[步长]=Get_Accuracy(y,Pred)dθ=梯度(θ。GET_LOSS(x,θ,y,L2_reg),θ)θ[:wxh],θ[:为什么]=θ[:wxh].-lr.*dθ[1][:wxh],θ[:为什么].-lr.*dθ[1][:为什么]if mod(Step,Disp_Every)==0val_x,val_y=get_xor(512,Size(X)[2]);PRED=f(val_x,θ)LOG_LOSS=LOG_LOSS(val_y,PRED)Accuracy=Get_Accuracy(val_y,PRED)println(";$Step Lost=$Accuracy";)#SAVE_FRAME(θ,STEP);End Returnθ,Loss,Acc End。
我们所有的功能都定义好了,现在是做好一切准备并开始培训的时候了。我们将使用StatsPlot软件包中的小提琴曲线图来显示权重分布是如何随时间变化的,方法是将Plot函数与!在位修改器将更多打印添加到当前地物。如果我们想要在每个笔记本单元格上显示1个以上的图形(确实如此),我们需要显式调用Display来显示我们想要显示的图形。
Dim_x=3 dim_h=4 dim_y=1 L2_reg=1e-4 LR=1e-2max_step=1400000θ=初始权重(dim_x,dim_y,dim_h)x,y=获取_xor(1024,dim_x)println(尺寸(X))plt=小提琴([";";],重塑(θ[:wxh],dim_x。,Alpha=0.5)小提琴!([";";],RESHAPE(θ[:为什么],dim_h*dim_y),Label=";为什么";,Alpha=0.5)Display(PLT)θ,Loss,Acc=Train(x,θ,y,max_Steps,LR,L2_reg)PLT=小提琴([";";],RESHAPE(θ[:wxh],dim。,Title=";Weight";,Alpha=0.5)小提琴!([";";],RESHAPE(θ[:为什么],dim_h*dim_y),Label=";为什么";,Alpha=0.5)显示(PLT)步数=1:大小(损失)[1]PLT=Plot(步数,损失,标题=";训练异或&34;,标签=";损失";)。)显示(PLT)。
最后,生成一个测试集来计算我们的模型与训练数据的过度拟合程度是个好主意。如果您运气不佳,并且模型的性能很差,请尝试更改一些超参数,如学习率或L2正则化。您还可以生成更大的训练数据集以获得更好的性能,或者尝试通过更改dim_h来更改隐藏层的大小。见鬼,您甚至可以修改代码以添加L1正则化或向MLP添加层,所以请尽情享受吧。
TEST_x,TEST_y=GET_XOR(512,3);PRED=f(TEST_x,θ);TEST_ACCENTITY=GET_ACCENTITY(TEST_y,PRED);TEST_LOSS=LOG_LOSS(TEST_Y,PRED);println(";测试损失和精度是$TEST_LOSS和$TEST_ACCENTITY&34;)&>;测试损失和准确率分别为0.03354685023541572和1.0。
当我们像这里一样按需生成数据时,测试数据集和验证数据集之间的区别是模糊的,但是通常您不会想要在静态测试数据集上运行模型之后返回并修改您的训练算法。这种行为有很高的数据泄露风险,因为您可以不断调整训练,直到获得良好的表现,但如果只在测试成绩良好时才停止,那么您实际上就已经决定了一个幸运的分数。这并没有告诉您模型将如何处理以前从未见过的实际测试数据,这在现实世界中经常发生,当研究人员集体迭代几个标准数据集时就会发生这种情况。当然,如果每个人都不断根据测试集调整他们的研究策略,MNIST每年都会有递增的改进!
无论如何,感谢您的光临,我希望您喜欢像我一样探索Julia的自动区分。



