ARM32内核如何启动
我上一篇关于内核如何解压缩的文章产生了大量的流量和评论,这让我非常惊讶。我猜想这可能是因为这类沉思与最初的狮子队在UNIX第6版上的评论有着相同的利基市场,源代码在20世纪70年代末曾大受欢迎。操作系统开发人员只是喜欢阅读扩展的代码注释,这就是事实。
当我谈论“ARM32”时,正确的ARM名称是Aarch32以及在ARMv4到ARMv7 ARM体系结构中物理实现的ARM名称。
在这篇文章中,我将讨论内核如何从解压/引导加载程序之后在物理内存中执行,一直到从虚拟内存执行用C编写的通用内核代码。
在解压缩之后以及在扩充和传递设备树BLOB(DTB)之后,通过将程序计数器PC置于符号stext()的物理地址(文本段的开始)来调用ARM32内核。可以在arch/arm/kernel/head.S中找到此代码。
宏\_\_head将这里的代码放在一个名为.head.text的链接器部分中,如果您在arch/arm/kernel/vmlinux.lds.S中检查ARM体系结构的链接器文件,您将看到这意味着这一部分中的目标代码将首先出现。
这将位于可被16MB整除的物理地址和额外的32KB text_offset(稍后将详细说明),因此您将发现stext()位于诸如0x10008000之类的地址,这是我们将在示例中使用的地址。
Head.S包含一个小森林,其中包含不同旧ARM平台的例外,因此很难区分树木和森林。ATAG和设备树引导的标准从编写之日起就有了,所以这些年来这个特殊的代码变得越来越复杂。
要理解以下内容,您需要对分页虚拟内存有一个基本的了解。如果维基百科过于简洁,请参考Hennesy&;Patterson的书“计算机体系结构:量化方法”。这意味着要了解一些ARM汇编语言和Linux内核基础知识。
让我们首先找出内核在虚拟内存中的实际执行位置。内核RAM基数在PAGE_OFFSET符号中定义,您可以对其进行配置。名称PAGE_OFFSET应理解为内核RAM的第一页的虚拟内存偏移量。
你在4个记忆分割选项中选择了1个,这让我想起了快餐店。目前在Arch/arm/Kconfig中定义如下:
CONFIG PAGE_OFFSET十六进制默认值PHYS_OFFSET IF!MMU默认值0x40000000 IF VMSPLIT_1G默认值0x80000000 IF VMSPLIT_2G默认值0xB0000000 IF VMSPLIT_3G_OPT默认值0xC0000000。
首先,请注意,如果我们没有MMU(例如在ARM Cortex-R类设备或旧的ARM7硅片上运行时),我们将在物理内存和虚拟内存之间创建1:1映射。然后,页表将仅用于填充高速缓存,并且不会重写地址。对于此类设置,PAGE_OFFSET通常位于地址0x00000000。在没有虚拟内存的情况下使用Linux内核被称为“uClinux”,在作为主线内核的一部分引入之前的几年里,它一直是Linux内核的分支。
在使用Linux或任何POSIX类型的系统时,不使用虚拟内存被认为是一件奇怪的事情。从现在开始,让我们假设使用虚拟内存启动。
PAGE_OFFSET虚拟内存分割符号在其上方的地址创建一个虚拟内存空间,供内核使用。因此,内核将其所有代码、状态和数据结构(包括虚拟到物理内存转换表)保存在虚拟内存中的以下位置之一:
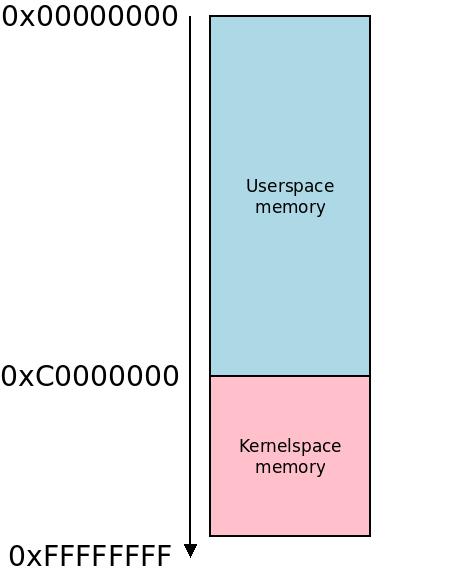
在这四个位置中,位于0xC0000000-0xFFFFFFFF的最后一个位置是迄今为止最常见的。因此,内核有1 GB的地址空间可供使用。
内核下面的内存(从0x00000000-PAGE_OFFSET-1开始,即通常位于地址0x00000000-0xBFFFFFFF(3 GB))用于用户空间代码。这与过度使用Unix的习惯相结合,这意味着您乐观地为程序提供了比您可用的物理内存更多的虚拟内存空间。每次启动新的用户空间进程时,它都会认为它有3 GB的内存可供使用!自20世纪70年代Unix系统问世以来,这种类型的过度使用一直是Unix系统的特征。
这很容易回答:ARM大量用于嵌入式系统,这些系统可以占用大量用户空间(例如普通平板电脑或手机,甚至是台式计算机),也可以占用大量内核(例如路由器)。大多数系统都占用大量用户空间,或者内存太少,拆分并不重要(两者都不会非常占用),所以最常见的拆分是使用PAGE_OFFSET 0xC0000000。
内核空间和用户空间内存之间最常见的虚拟内存划分是0xC0000000。注意这些插图:当我说记忆在“上面”时,我指的是图片中较低的位置,沿着箭头,朝向较高的地址。我知道有些人认为这是不合逻辑的,并且把数字颠倒过来,上面有0xFFFFFFFF,但这是我个人的喜好,也是大多数硬件手册中使用的惯例。
可能会出现这样的情况:您拥有大量内存和大量内核的用例,例如具有大量内存的路由器或NAS,比如整整4 GB的RAM。然后,您希望内核能够将部分内存用于页面缓存和网络缓存,以加速最典型的用例,因此您将选择一个可以提供更多内核内存的拆分,例如在极端情况下PAGE_OFFSET 0x40000000。
当内核执行用户空间代码时,此虚拟内存映射始终存在。其想法是,通过不断映射内核,上下文从用户空间到内核空间的切换变得非常迅速:当用户空间进程想要向内核请求某些东西时,您不需要替换任何页表。您只需发出一个软件陷阱来切换到管理程序模式并执行内核代码,虚拟内存设置就会保持不变。
不同用户空间进程之间的上下文切换也变得更快:您只需要替换页表的较低部分,通常内核映射很简单,它使用预定的物理RAM块(开始加载它的物理RAM),并且是线性映射的,甚至存储在一个特殊的位置,即转换后备缓冲区。翻译后备缓冲器,“硅片中的特殊快速翻译表”,使得进入内核空间的速度更快。这些地址始终存在,始终线性映射,并且永远不会生成页面错误。
下一步是处理我们在某个未知的内存位置上运行的事实。内核可以加载到任何地方(只要它是一个合理的均匀地址),并且可以直接执行,所以现在我们需要处理这个问题。由于内核代码不是位置独立的,因此在编译之后,链接器立即将其链接到某个地址执行。我们还不知道那个地址。
内核首先检查一些特殊功能,如虚拟化扩展和LPAE(大型物理地址扩展),然后执行以下操作:
ADR R3,2f ldmia R3,{R4,R8}subR4,R3,R4@(phys_OFFSET-PAGE_OFFSET)加上R8,R8,R4@phys_Offset(...)2:.long。.long page_Offset
.Long。是分配给标签2的地址的链接时间:自身,所以。被解析为标签2:实际链接到的地址,链接器认为它将位于内存中。此位置将位于分配给内核的虚拟内存中,即通常高于0xC0000000的某个位置。
之后是编译的常量PAGE_OFFSET,我们已经知道它类似于0xC0000000。
我们将编译时地址IF 2:加载到R4中,并将常量PAGE_OFFSET加载到R8中。然后,我们从R4中使用相关指令在R3中获得的实际地址2:中减去它。请记住,手臂装配参数顺序类似于袖珍计算器:subra,rb,rc=>;ra=rb-rc。
结果是,我们在R4中获得了内核编译要运行的地址和内核实际运行的地址之间的偏移量。所以注释@(phys_Offset-page_Offset)表示我们有这个偏移量。如果内核符号2:在虚拟内存中编译为在0xC0001234执行,但我们现在在0x10001234执行,则R4将包含0x10001234-0xC0001234=0x50000000。这可以理解为“-0xB0000000”,因为该算术是可交换的:0xC0001234+0x50000000=0x10001234,QED。
接下来,我们将此偏移量添加到编译时分配的page_offset中,我们知道该偏移量类似于0xC0000000。使用回绕算法,如果我们再次在0x10000000执行,我们得到0xC0000000+0x50000000=0x10000000,并且我们获得了内核当前在r8中实际执行的基物理地址-因此注释为@phys_offset。R8中的此值是我们实际要使用的值。
老ARM内核有一个名为plat_phys_offset的符号,它正好包含这个偏移量(例如0x10000000),尽管分配了编译时间。我们不再这样做了:我们动态地分配它,就像我们将看到的那样。如果您正在使用不如Linux复杂的操作系统,您会发现开发人员为了简单起见通常只是假设如下:物理偏移量是一个常量。Linux已经发展到这一步,因为我们需要在所有类型的内存布局上处理单个内核映像的引导。
我不知道这张图片是让事情更容易理解还是更难理解。在我们的示例中,它说明了物理内存到虚拟内存的映射。
Phys_Offset有一些规则:它需要遵守一些基本的对齐要求。当我们确定解压缩代码中第一个物理内存块的位置时,我们执行phys=pc&;0xF8000000,这意味着物理RAM必须从128MB的边界开始。例如,如果它从0x00000000开始,那就很棒了。
当内核从ROM(只读内存)执行时,对于XIP“就地执行”情况,有一些关于此代码的特殊注意事项,但我们撇开这一点不谈,它是另一个奇怪之处,甚至比不使用虚拟内存更少见。
还要注意一件事:您可能试图加载一个未压缩的内核并引导它,并且注意到内核对放置它的位置特别挑剔:您最好将它加载到一个物理地址,比如0x00008000或0x10008000(假设您的text_offset是0x8000)。如果您使用压缩内核,您可以避免这个问题,因为解压缩器会将内核解压缩到一个合适的位置(通常是0x00008000),并为您解决这个问题。这就是为什么人们可能会觉得压缩内核“只是工作”的另一个原因,而且这是一种常态。
现在我们有了将要执行的虚拟内存和实际执行的物理内存之间的偏移量,接下来我们将看到KCONFIG符号CONFIG_ARM_PATCH_PHYS_VIRT的第一个符号。
之所以创建此符号,是因为开发人员正在创建需要在不同内存配置的系统上引导的内核,而无需重新编译内核。内核将被编译为在某个虚拟地址(如0xC0000000)执行,但也可以在0x10000000(如我们的示例)处加载到内存中,也可以在0x40000000(或其他地址)处加载到内存中。
当然,内核中的大多数符号都不需要注意:它们在它们所链接的地址的虚拟内存中执行,并且我们始终在0xC0000000上运行它们。但是现在我们不是在编写一些用户空间程序:事情并不容易。我们必须了解正在执行的物理内存,因为我们是内核,这意味着我们需要在页表中设置物理到虚拟的映射,并定期更新这些页表。
此外,因为我们不知道我们将在物理内存中的什么位置运行,所以我们不能依赖任何廉价的技巧,如编译时常量,这是作弊,并且很难维护充满幻数的代码。
为了在物理地址和虚拟地址之间进行转换,内核有两个函数:__virt_to_phys()和__phys_to_virt()在每个方向上转换内核地址(不是内核内存使用的地址以外的任何其他地址)。此转换在内存空间中是线性的(在每个方向上使用一个偏移量),因此应该可以通过简单的加法或减法来实现这一点。这就是我们开始做的事情,我们将其命名为“P2V运行时修补”。该方案由Nicolas Pitre、Eric Miao和Russell King于2011年发明,Santosh Shilimkar在2013年将该方案扩展到也适用于LPAE系统,特别是TI Keystone SoC。
主要观察结果是,如果它支持内核物理地址PHY和内核虚拟地址VIRT(您可以通过查看最后一个插图来确信这两个):
因此,可以总是通过加法常数从虚拟地址计算物理地址,并且通过减法QED从物理地址计算虚拟地址。这就是为什么初始存根看起来是这样的:
静态内联无符号long__virt_to_phys(无符号长x){unsign long t;__pv_stub(x,t,";add";);return t;}静态内联无符号long__phys_to_virt(无符号长x){无符号长t;__pv_stub(x,t,";;sub";);return t;}。
__pv_stub()将包含要进行加法或减法的汇编宏。从那时起,LPAE对超过32位地址的支持使这段代码变得更加复杂,但总体思路是相同的。
每当在内核中调用__virt_to_phys()或__phys_to_virt()时,都会将其替换为来自arch/arm/include/asm/memory y.h的一段内联汇编代码,然后链接器将区段切换到名为.pv_table的区段,然后向该区段添加一个条目,并将指针指向它刚刚添加的汇编指令。这意味着.pv_table部分将展开为指向这些内联程序集的任何实例的指针表。
在引导期间,我们将遍历该表,获取每个指针,检查它所指向的每条指令,使用我们实际加载的物理和虚拟内存的偏移量为其打补丁。
在早期引导过程中,使用汇编宏执行从物理内存到虚拟内存转换的每个位置都会打上补丁。
为什么我们要进行这种复杂的处理,而不是只将偏移量存储在变量中?这是出于效率原因:它位于内核的热数据路径上。更新页表和交叉引用物理到虚拟内核内存的调用对性能非常关键,所有使用内核虚拟内存的用例,无论是块层或网络层操作,还是用户到内核空间的转换,原则上任何通过内核的数据,都会在某个时候调用这些函数。他们一定跑得很快。
称这是问题的简单解决方案是错误的。唉,这是一个非常复杂的问题解决方案。但是它很管用,而且效率很高!
我们通过计算如上所示的偏移量并迭代修补所有程序集存根来执行实际修补。这是在对符号__FIXUP_PV_TABLE的调用中完成的,在这里我们刚刚在R8中计算的偏移量开始发挥作用:需要直接引用物理内存的5个符号的表(称为__PV_TABLE)被读取到寄存器R3中。使用与上述相同的方法扩充了R7(这就是表格前面带有.long的原因):
__FIXUP_PV_TABLE:ADR R0,1f ldmia R0,{R3-R7}MVN IP,#0 Subs R3,R0,R3@phys_Offset-page_Offset添加R4,R4,R3@调整表起始地址添加R5,R5,R3@调整表结束地址添加R6,R6,R3@ADJUST__PV_PHYS_PFN_OFFSET地址添加R7,R7,R3@ADJUST__PV。[版本6]@将计算的PHYS_OFFSET保存到__PV_PHYS_PFN_OFFSET(...)B__Fixup_a_PV_Table1:.long。.long__PV_TABLE_BEGIN.long__PV_TABLE_END2:.long__PV_PHYS_PFN_OFFSET.Long__PV_OFFSET。
代码使用加载到R3中的第一个值来计算物理内存的偏移量,然后将其添加到其他每个寄存器,以便R4到R7现在直接指向每个标签中包含的物理内存。因此,R4是指向存储__PV_TABLE_BEGIN的物理内存的指针,R5指向__PV_TABLE_END,R6指向__PV_PHYS_PFN_OFFSET,R7指向__PV_OFFSET。在C语言中,这些是u32*,所以指向一些32位数字的指针。
__PV_PHYS_PFN_OFFSET特别重要,这意味着修补物理到虚拟页帧编号的偏移量,因此我们首先通过使用之前在R8中计算的值(在我们的示例中是从0到内核内存的偏移量0x10000000)通过mov r0,r8,lsr#page_shift进行逻辑右移,然后将其直接写入任何实际存储字符串r0,[r6]的变量的位置。这不是在内核启动的早期阶段使用的,但稍后将由虚拟内存管理器使用。
接下来,我们调用__fixup_a_pv_table,它将遍历从R4到R5的地址(指向要打补丁的指令的指针表),并使用自定义的二进制补丁程序按顺序对每个地址进行补丁,该补丁程序将ARM或THUMB2(指令集在编译时已知)中的指令转换为直接编码到其中的物理和虚拟内存之间的立即偏移量。该代码相当复杂,并且还包含适应高端字节顺序的怪癖。
请注意,每次内核加载模块时也必须执行此操作,谁知道新模块是否需要在物理地址和虚拟地址之间进行转换!因此,所有模块ELF文件都将包含具有相同类型表的.pv_table部分,并且每次加载模块时也会调用完全相同的程序集循环。
在我们可以开始在刚刚挖出的虚拟内存中执行之前,我们需要设置一个MMU转换表,用于将物理内存映射到虚拟内存。这通常被称为页表,尽管初始映射将使用的不是页面,而是部分。ARM体系结构要求必须将其放置在物理内存中的偶数16KB边界上。因为它的大小也总是16KB,所以这是有意义的。
初始页表的位置在一个名为swapper_pg_dir的符号中定义,“swapper page directory”,这是内核初始页表的惯用名称。正如您所意识到的,它稍后将被更精细的页表取代(交换,因此称为“交换器”)。
“页表”这个名称有点误导,因为在ARM术语中初始映射使用的实际上是节,而不是页。但这个术语用来指代“在引导时将物理地址转换为虚拟地址的东西”有点模糊。
符号swapper_pg_dir定义为KERNEL_RAM_VADDR-PG_DIR_SIZE。让我们逐一检查一下。
KERNEL_RAM_VADDR正是您所怀疑的:内核所在的虚拟内存中的地址。它是编译期间内核链接到的地址。
KERNEL_RAM_VADDR定义为(PAGE_OFFSET+TEXT_OFFSET)。PAGE_OFFSET可以是我们刚才调查的KCONFIG符号的四个位置之一,通常为0xC0000000。TEXT_OFFSET通常为0x8000,因此KERNEL_RAM_VADDR通常为0xC0008000,但是如果使用不同的虚拟内存分割设置或外来的TEXT_OFFSET,则会有所不同。Text_offset来自ARCH/ARM/Makefile中的textof-y,通常为0x8000,但在某些高通平台上也可以是0x00208000,在某些Broadcom平台上也可以是0x00108000,从而使kernel_R。
.