良性数据竞赛被认为是有害的
关于所谓的良性数据竞赛的一系列帖子引发了很多争议,并在我工作的一家名为Corensic的初创公司引发了大量讨论。形成了两个堡垒,一个声称没有数据竞赛是良性的,另一个声称数据竞赛对性能至关重要。后来发现,我们甚至无法就数据竞赛的定义达成一致。特别值得一提的是,C++11的定义似乎偏离了既定的概念。
首先,让我们确保我们知道我们在说什么。在当前使用中,数据竞争等同于低级数据竞争,而不是涉及多个存储器位置或每个线程多个访问的高级竞争。每个人都同意数据冲突的含义,即多个线程访问相同的内存位置,其中至少有一个线程通过写入。但数据冲突不一定是数据竞赛。为了让它成为一场比赛,还必须有一个条件成立:访问必须是“同时进行的”。
不幸的是,在并发系统中,同时性并不是一个定义良好的术语。莱斯利·兰波特(Leslie Lamport)是第一个观察到分布式系统遵循狭义相对论规则的人,他没有独立的同时性概念,而是伽利略力学的规则和绝对时间。所以,真的,数据竞赛的定义取决于你对同时性的概念。
也许更容易定义哪些不是同步的,而不是什么是同步的?事实上,如果我们能说出哪个事件发生在另一个事件之前,我们就可以确定它们不是同时发生的。因此,在定义数据竞赛时使用了著名的“发生在此之前”关系。在狭义相对论中,这种关系是通过信息交换建立起来的,信息的传播速度不能超过光速。发送消息的动作总是发生在接收相同消息的动作之前。在并发编程中,这种连接是使用同步操作建立的。因此,对数据竞争的另一种定义是:没有干预同步的内存冲突。
同步操作的最简单示例是获取和释放锁。假设有两个线程执行此代码:
在任何实际执行中,从两个线程对共享变量x的访问将由同步分隔。在此之前发生事件(HB)箭头将始终从一个释放锁的线程指向另一个获取锁的线程。例如,在以下位置:
HB箭头从3到4,清楚地将冲突的访问分隔为2和5。
注意字眼的谨慎选择:“实际执行”。如果互斥确实保证了互斥,则包含争用的以下执行永远不会发生:
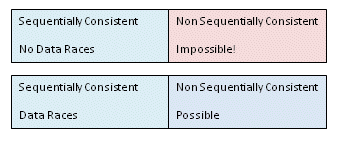
事实证明,选择可能的执行在定义数据竞赛中扮演着重要的角色。在我所知的每个内存模型中,在测试数据竞争时只尝试顺序一致的执行。请注意,实际上可能会发生非顺序一致的执行,但它们不会进入数据竞争测试。
事实上,大多数语言都试图提供所谓的DRF(无数据竞争)保证,即所有无数据竞争程序的执行都是顺序一致的。不要对参数的明显循环性感到恐慌:您可以从顺序一致的执行开始,以证明数据竞争自由,如果您没有发现任何数据竞争,您就会得出结论,所有的执行都是顺序一致的。但是,如果您确实以这种方式发现了数据竞赛,那么您就知道非顺序一致的执行也是可能的。
正如您所看到的,为了定义数据竞争,您必须准确定义“同步”或“同步”的意思,并且必须指定您的定义可以应用于哪些执行。
在Java中,除了通过“同步”方法访问的传统互斥锁之外,还有另一种称为易失性变量的同步设备。对易失性变量的任何访问都被视为同步操作。您不仅可以在同一对象的连续解锁和锁定之间,也可以在对易失性变量的连续访问之间绘制发生在前的箭头。考虑到这个扩展,Java提供了传统的DRF保证。无数据竞争程序的语义按照顺序一致性进行了很好的定义,因此让每个Java程序员都感到高兴。
但是Java并没有止步于此,它还试图至少为具有数据竞争的程序提供一些少量的语义。这个想法是高尚的-只要程序员是人,他们就会写出有缺陷的程序。很容易宣称任何具有数据竞争的程序都表现出未定义的行为,但是如果这种未定义的行为导致严重的安全漏洞,人们就会变得非常紧张。因此,Java内存模型在DRF之上保证的是,数据竞争导致的未定义行为不会导致程序中出现无中生有的值(例如,入侵者的安全凭据)。
现在人们普遍认识到,这种定义数据竞争语义的尝试已经失败,Java内存模型被打破(我这里引用的是Hans Boehm)。
为什么对数据竞赛有一个良好的定义是如此重要?是因为DRF保证吗?这似乎是Java内存模型背后的动机。数据竞争的缺失定义了顺序一致的程序子集,因此具有定义良好的语义。但是这两个属性:顺序一致和语义定义良好并不一定是相同的。毕竟,Java试图(尽管没有成功)为非顺序一致的程序定义语义。
因此,C++选择了一种略有不同的方法。C++内存模型基于将所有程序划分为三类:
第一类非常类似于无竞争的Java程序。Java Volatile的位置由C++11默认原子取代。“默认”这个词在这里至关重要,我们稍后会看到。就像在Java中一样,DRF保证适用于这些程序。
这是引起所有争议的第二个类别。引入它与其说是出于安全性,不如说是出于性能原因。在大多数多处理器上,顺序一致性是昂贵的。这就是为什么许多C++程序员目前求助于“良性的”数据竞争,即使冒着未定义行为的风险。汉斯·博姆(Hans Boehm)的论文“如何错误编译具有”良性“数据竞赛的程序”,对这些方法造成了致命的打击。他举例说明了合法的编译器优化可能会对具有“良性”数据竞争的程序造成严重破坏。
幸运的是,C++11允许您以受控的方式放松顺序一致性,这将高性能与定义良好(如果复杂)的语义的安全性结合在一起。因此,第二类C++程序使用具有宽松内存排序语义的原子变量。以下是我上一篇博客文章中的一些典型语法:
这里是有争议的部分:根据C++内存模型,放松的内存操作(如上面的负载)不会导致数据竞争,即使它们不被认为是同步操作。还记得数据竞赛定义的一个版本吗:冲突的操作而不干预同步?这个定义不再适用了。
C++标准决定,只有没有定义语义的冲突才称为数据竞争。
请注意,某些形式的松弛原子可能会引入同步。例如,如果在特定执行中,使用MEMORY_ORDER_RELEASE的写访问“发生在”使用MEMORY_ORDER_ACCENTER的另一次访问之前(但如果相反的话!)。
这对C++11程序员意味着什么?这意味着不再有数据竞赛的借口。如果您需要良性的数据竞争来提高性能,那么可以使用弱原子重写您的代码。弱原子为您提供了与良性数据竞赛相同的性能,但它们具有定义良好的语义。传统的“良性”竞争可能会通过优化编译器或在棘手的架构上被打破。但是如果您使用弱原子,编译器将应用任何必要的方法来强制执行正确的语义,并且您的程序将始终正确执行。它甚至会自然地对齐原子变量,以避免损坏的读写操作。
更重要的是,由于C++11具有定义良好的内存语义,编译器编写者不再被迫保守地进行优化。如果程序员没有明确地将共享变量标记为原子,编译器就可以像优化单线程一样自由地优化代码。因此,即使在相对简单的体系结构(如x86)上,也不能保证所有这些良性数据竞争的聪明技巧都能奏效。例如,编译器可以自由地使用您的损耗计数器或二进制标志进行自己的临时存储,只要稍后将其恢复即可。如果其他线程通过竞争代码访问这些变量,它们可能会将任意值视为“未定义行为”的一部分。你已经被警告过了!关注@BartoszMilewski
对于标准的SMP内核,竞争是不可避免的,这是不使用该架构的原因之一-如果您的代码中有互斥体,您的编程级别可能太低,最好使用一种隐藏这些内容并保证可预测结果的语言-基于CSP的语言。



