Google开源LIT,一个评估自然语言模型的工具集
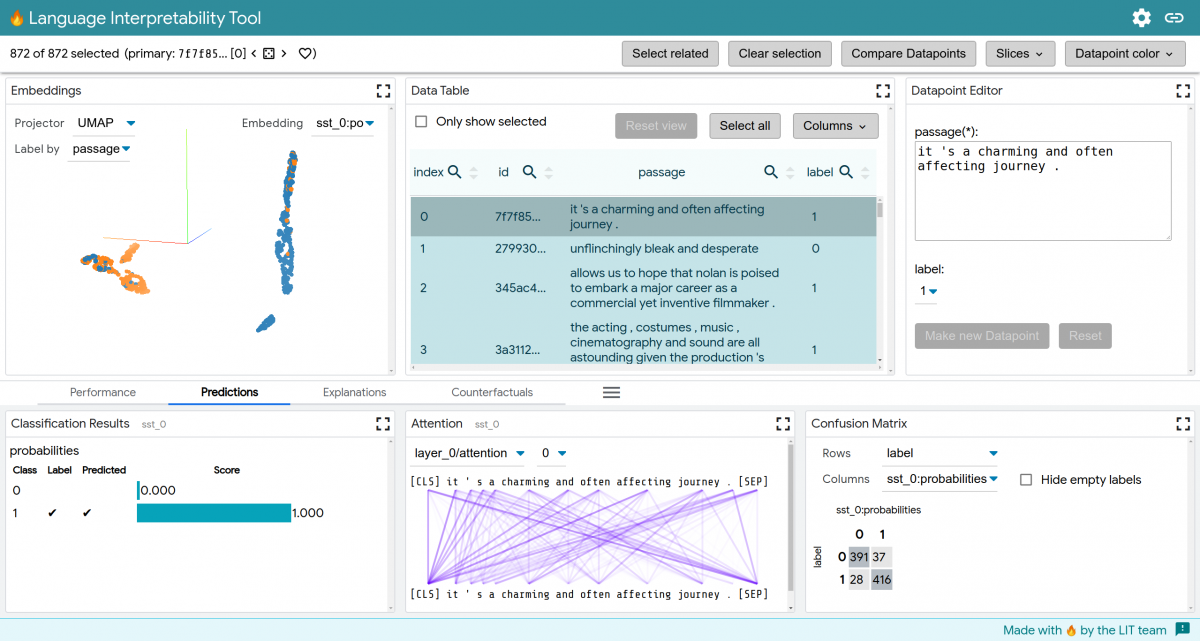
Google下属的研究人员今天发布了语言可解释性工具(LIT),这是一个开源的、与框架无关的平台和API,用于可视化、理解和审计自然语言处理模型。它集中在关于人工智能模型行为的问题上,比如为什么模型做出某些预测,为什么他们在输入语料库中表现不佳。LIT将聚合分析合并到一个基于浏览器的界面中,该界面旨在实现对文本生成行为的探索。
建模方面的进步导致了自然语言处理任务的空前性能,但关于模型是否倾向于按照偏见和启发式行事的问题仍然存在。没有分析的灵丹妙药-数据科学家必须经常使用几种技术来建立对模型行为的全面理解。
这就是LIT的用武之地。该工具集的架构使得用户可以在可视化和分析之间跳跃,以测试假设并在数据集上验证这些假设。可以即时添加新的数据点,并立即可视化它们对模型的影响,而并行比较允许同时可视化两个模型或两个数据点。LIT计算并显示整个数据集的度量,以突出模型性能中的模式,包括当前选择、手动生成的子集和自动生成的子集。
LIT支持广泛的自然语言处理任务,如分类、语言建模和结构化预测。它的创建者声称,它是可扩展的,可以为新的工作流重新配置,并且组件是独立的、可移植的,并且易于实现。谷歌的研究人员说,Lit可以在任何可以从Python运行的模型上运行,包括TensorFlow、PyTorch和服务器上的远程模型。而且它的进入门槛很低,只需要少量的代码来添加模型和数据。
为了证明LIT的稳健性,研究人员在情绪分析、性别去偏见和模型调试方面进行了一系列案例研究。他们展示了工具集如何暴露在开放源码OntoNotes数据集上训练的共指模型中的偏见,例如,揭示某些职业在哪里与高比例的男性工人相关联。LIT背后的谷歌开发人员在一篇技术论文中写道:“在LIT的度量表中,我们可以根据代词类型和真正的参照物来划分选择。”“在男性占主导地位的职业集合上,我们发现,当基本事实与刻板印象相符时,该模型表现良好--例如,当答案是职业术语时,男性代词正确解析的比例为83%,而女性代词正确解析的比例仅为37.5%。”
该团队警告说,LIT不能很好地扩展到大型语料库,而且它对培训时间模型监控也不是“直接”有用的。但他们表示,在不久的将来,该工具集将获得诸如反事实生成插件、序列和结构化输出类型的额外度量和可视化,以及为不同应用程序定制UI的更大能力。



