西兰花:同步更快,同步更少
Dropbox每天跨数百万个桌面客户端同步数PB的数据。我们必须不断改善用户的同步体验,以提高用户在日常生活中的工作效率。我们还不断努力更好地利用我们的基础设施,提高Dropbox的运营效率。因为文件本身是在同步过程中发送到Dropbox和从Dropbox发送的,所以我们可以利用常见文件格式中的冗余和重复模式来更简洁地发送文件,从而提高性能。现代压缩技术使用短位代码识别并保存这些冗余和模式,以将大文件传输为较小的、无损压缩的文件。因此,在同步文件之前压缩文件意味着网络上的数据更少(降低了最终用户的带宽使用率和延迟!)。并在后端存储较小的部分(增加了存储成本节约!)。为了实现这些改进,我们在Dropbox的传入数据流上测试了几种常见的无损压缩算法,包括7zip、zstd、zlib和Brotli,我们选择使用稍微修改过的Brotli编码器(我们称为Broccoli)在同步之前压缩文件。
今天,我们将深入了解Broccoli编码,概述块同步协议,并解释如何将它们结合使用来优化块数据传输。总而言之,这些改进减少了30%以上的中位延迟,并减少了相同数量的线路上的数据。我们将谈论我们牢记的原则和我们在这一过程中学到的东西。我们还将谈到我们的新投资在未来如何帮助我们。
我们最近完成了一项非常雄心勃勃的同步引擎系统(代号为“Nucleus”)的重写。这次重写给了我们一个机会,让我们重新思考十年来的假设,重新想象下一次假设最适合我们的是什么。虽然我们的文件同步协议中的压缩并不是一个新的优化,但自从我们建立了最初的同步引擎以来,新的压缩研究已经解锁了一系列新的算法。当我们推出Nucleus时,我们对新压缩选项的批判性分析带来了更好的性能。
我们之前使用zlib已经有很多年了,但是我们的测量表明,使用更新的算法可以做得更好。虽然Dropbox已经对通用文件压缩算法和Lepton(一种新的图像重新压缩算法)进行了研究,但这些技术并不适合在客户机上以网络速度运行。
文件大小:Brotli可以在运行时使用Unicode或二进制上下文字节动态选择H uffman表,这使得最终文件大小有多个百分点的差异。
预编码:由于驻留在我们的持久性存储Magic Pocket中的大部分数据已经使用Broccoli进行了Brotli压缩,因此我们可以避免在块下载协议的下载路径上进行重新压缩。这些预编码的Brotli文件具有延迟优势(因为它们可以直接交付给客户端)和大小优势(因为Magic Pocket包含以更高压缩质量级别优化的Brotli编码)。
安全性:Nucleus是用Rust编写的,只有Brotli和zlib在Rust的安全子集中有实现。这意味着即使客户端故意发送Dropbox篡改的数据,解压缩器也会抵抗错误和崩溃。
熟悉度:我们已经在利用Brotli作为我们的静态网络资产的主要来源。
HTTP支持:Brotli是HTTP流压缩的标准,因此选择Brotli格式的文件允许我们使用相同的格式发送到Web浏览器和Nucleus。
我们在“铁锈”一书中将Brotli压缩器的代号命名为“西兰花”,因为它能够使Brotli文件相互连接(brot-cat-li)。我们决定用西兰花包装,因为它是:
速度更快:我们能够以普通Google Brotli的3倍速度压缩文件,使用多个内核压缩文件,然后将每个块连接起来。
过程中,使用简单:西兰花是一个来自Python的函数调用和GOlang中的Reader/Writer接口。由于Dropbox对运行原始C代码有严格的安全要求,谷歌的Brotli将需要在一个专门制作的低权限监狱中运行,这会带来持续的数据维护成本和显著的性能下降,特别是对于小文件。
要解锁多线程压缩(和拼接能力),我们需要压缩文件块并生成有效的Brotli输出。在我们的设计过程中,我们发现原始Brotli协议的一个子集,如果修改,可以允许文件在压缩后缝合在一起。阅读下面附录中有关我们所做更改的更多信息。
在下面的部分中,我们将总结我们的桌面客户端如何上传和下载文件,以帮助解释我们如何将Broccoli分层到协议中。客户端同步协议由两个子协议组成:一个用于同步文件元数据,例如文件名和大小,另一个用于同步块,这些块是高达4兆字节(MIB)的文件的对齐块。这第一部分(元数据同步协议)暴露了块同步引擎的接口,以知道需要上载或下载哪些块来完成同步过程并达到同步完成状态。今天我们将重点介绍第二部分,块同步协议。
块同步协议实现了在客户端和服务器之间传输数据的简单接口。剔除与身份验证和各种其他优化相关的附加信息后,该协议如下所示:
RPC PutBlock(PutBlockRequest)返回PutBlockResponse;RPC GetBlock(GetBlockRequest)返回GetBlockResponse;消息PutBlockRequest{bytes block_hash=1;bytes block=2;}message PutBlockResponse{}message GetBlockRequest{bytes block_hash=1;}message GetBlockResponse{bytes block=1;}
要执行上传,客户端使用PutBlock端点并提供块和块散列。这允许我们检查服务器上的散列,以断言数据在网络上没有损坏。下载时,我们通过GetBlock端点要求服务器返回特定块散列的块。在服务器上,存储层然后与Magic Pocket通信以存储和检索块。
对于上传,路径非常清晰,因为我们已经允许在存储层上进行压缩。我们现在需要向新压缩的块提供块格式和未压缩块的散列。
消息PutBlockRequest{bytes block_hash=1;bytes block=2;//描述需要何种压缩类型的枚举。BlockFormat block_format=3;}消息PutBlockResponse{}。
我们需要未压缩块的散列,因为既然我们已经在压缩中添加了一层优化,那么我们也暴露了一个持久性问题。现在,在压缩客户端上的块时可能会损坏,因为我们的客户端很少有ECC内存。我们看到,内存损失率一直很高,端到端的完整性验证总是有回报的。
请求路径上的额外解压缩调用可能代价很高,但需要确保压缩文件对原始文件进行编码。考虑耐用性和性能之间的艰难权衡对我们来说实际上非常容易,因为我们总是可以选择耐用性,因为这一直是Dropbox基础设施的赌注原则。西兰花减压很便宜,但我们仍然需要知道它是否不是微不足道的,它是否会产生比仅仅增加潜伏期更多的影响。例如,我们现在可能需要扩展机器的数量。当我们对不同类型文件的不同数据块大小(最大为4MiB)进行基准测试时,我们意识到此检查在每个核心每秒300 MiB以上运行,这是我们愿意为改善总体延迟和节省存储而付出的成本。
对于上传路径,我们注意到每天平均节省的带宽百分比约为33%。每天汇总并标准化后,50%的用户节省了约13%,25%的用户节省了约40%,10%的用户在上传文件时节省了约70%,获益最大。
请求的平均大小的p50从每个请求的3.5MiB降到了大约1.6MiB。我们没有看到p75请求大小有任何显著变化,这表明Dropbox托管和服务的四分之一以上的数据是不可压缩的。这并不令人惊讶,因为大多数视频和图像在很大程度上是西兰花无法压缩的。至于潜伏期,p50再次大幅下降,平均提高了约35%。
请注意请求大小和延迟是如何周期性波动的。当按星期几分组时,我们看到这些数字在周末差异很大,这表明用户通常在工作日处理高度可压缩的文件,如电子邮件、Word和pdf文档,而在周末处理更多不可压缩的内容,如电影和图片,这表明用户通常在工作日处理高度可压缩的文件,如电子邮件、Word和PDF文档,而在周末处理更多不可压缩的内容,如电影和图片。
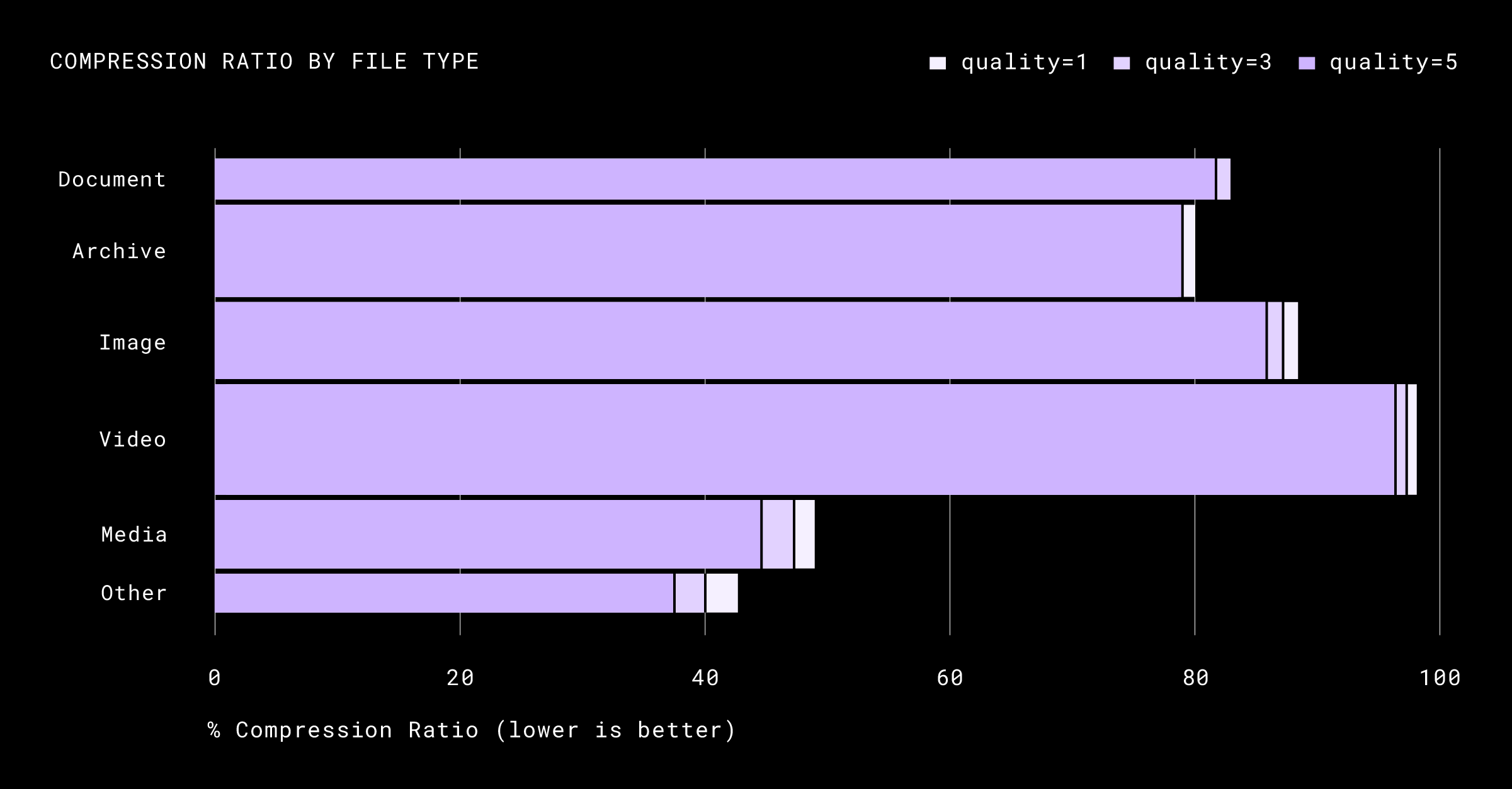
如果我们按文件扩展名细分上传,我们注意到节省的大部分来自非图像介质、归档和文档。下图显示了传入文件在不同质量级别下的压缩节省。每个条形图的垂直大小说明了未压缩文件占所有上传内容的比例。条形图的面积表示在应用了图示的三个花椰菜压缩质量选项中的每一个后,它在Dropbox的网络管道中占据了多少空间。
在我们网络团队中的一位好奇的工程师发现压缩实际上是高带宽连接(100 Mbps以上的链路)的瓶颈之前,上述更改进行得相当顺利。西兰花允许我们设置质量级别,我们已经选择了用于持久长期储存的精确设置,即质量=5,窗口大小=4MiB。在基准测试之后,我们决定继续使用较低的质量级别来消除这一瓶颈,但代价是压缩的数据稍微大一些。这一决定是基于将用户放在第一位的原则,以避免文件上传的更高延迟,即使这对我们来说意味着服务器上的网络使用量有所增加。进行此更改后,我们看到较大文件的上传速度有了显着提高,因为我们比以前占用了更多的带宽。当我们开始思考这个问题时,压缩成为瓶颈的可能性对我们来说并不明显,这是一个完美的提醒,让我们不断挑战我们的假设。
虽然我们的总体节省百分比从~33%下降到~30%,但我们设法将大文件上传带宽从~35 Mbps加快到~50 Mbps(峰值),从而提高了上传链路吞吐量。
下载路径稍微复杂一些,因为我们可以采取不同的方法。选择压缩格式可以是客户端驱动的,也可以是服务器驱动的。我们最终将两者结合起来,将客户端作为主要驱动程序,但允许服务器帮助指导客户端,以便更好地后退到更简单的格式。
消息GetBlockRequest{字节BLOCK_HASH=1;BlockFormat BLOCK_FORMAT=2;}消息GetBlockResponse{字节块=1;BlockFormat BLOCK_FORMAT=2;}。
这种灵活性避免了客户端-服务器版本偏差问题,并且从理论上讲,它允许过载的服务器在繁忙的流量期间跳过压缩并返回原始字节。让服务器控制发送到客户端的值的另一个好处是,由于数据仅在服务器上可用,我们可以决定压缩是否是向下发送块的最有效方式。重要的是要注意,在数据是不可压缩的情况下,Brotli会在上面添加额外的字节,以使压缩块的大小大于其未压缩版本。对于较小的块,这种情况发生得更频繁,因为当我们从Magic Pocket获取数据时,我们知道块的大小,所以我们可以决定将数据作为未压缩的数据返回。随着我们继续收集更多关于哪些案例比其他案例更常见的数据,我们可以针对这些相对较小的性能胜利。
通过下载压缩,我们注意到所有请求的平均每天节省约为15%。按主机归一化后,我们发现50%的用户节省了8%,25%的用户节省了20%左右,10%的用户从下载压缩中获益最多,节省了50%左右。
请求大小的p50从3.4MiB降至1.6MiB。与我们在上传压缩结果中看到的不同,压缩下载对延迟的影响很大。我们看到P90改进了12%,P75改进了27%,P50改进了50%。
虽然大多数客户端的带宽没有太大变化,但我们看到P99的平均日带宽从80 Mbps提高到了100 Mbps(峰值)。这可能意味着高带宽连接通过此更改从其下载链接中获得了更多。
当其中一个客户端崩溃时,在我们内部Alpha推出的早期阶段(仅针对Dropbox员工),在下载路径中进行更改时遇到了一个小问题。我们有一个零崩溃策略,并尝试设计桌面客户端以从每个已知问题中恢复。一般来说,我们认为当我们达到稳定时,一个客户端在内部alpha中崩溃可能会导致数千个客户端崩溃。经过进一步调查,我们发现客户端的解压路径存在两个问题:解压库中有一个bug,我们期待解压永远不会失败。我们通过以下方式修复了这个问题:关闭服务器上压缩下载的发送,将补丁上游提交到rust-brotli-unpressor,并允许在解压缩失败时回退到普通下载,而不是在客户机上崩溃。这个问题验证了在稳定发布之前有一个内部alpha,以及我们在决定压缩技术时选择的混合客户端-服务器协议。至于崩溃,很明显,我们希望通过回退到普通路径并提醒压缩故障,再次在优化路径中出现错误时出现故障。
在未来,只要我们能检测到底层数据是不可压缩的,就会有减少CPU时间的空间。我们可以考虑使用以下技术:
在Dropbox中维护最常见的不可压缩类型的静态列表,并对其执行恒定时间检查,以决定是否要压缩块。
在压缩上传之前,检测我们的上传链接是否饱和或压缩时是否被阻止,然后动态决定相关的质量级别和窗口大小组合。
使用计算字节流的高斯分布和香农熵的启发式算法来过滤可能的不可压缩块。
我们要感谢Alexey Ivanov、Geoffry Song、John Lai、Rajat Goel、Jongmin Baek和Mehant Baid提供的宝贵反馈。我们还要感谢同步和存储团队荣休,感谢他们在这方面所做的贡献。
Brotli压缩数据由报头和一系列元块组成。每个元块内部包含其自己的报头(其描述压缩部分的表示)和压缩数据。压缩数据由一系列命令组成,其中每个命令都有一个文字字节序列和一个指向重复字符串的指针,该指针表示为一对<;长度,向后距离>;。这些命令使用前缀代码来表示,前缀代码的描述被压缩在元块报头内。这些命令还使用全局上下文来破译如何应用这些前缀代码,以及如何反向引用包含公共冗余的全局静态字典。最终的未压缩数据是每个元块的未压缩序列的级联。
上面提到的一些便利使得在O(1)时间内进行级联变得困难。为了解决阻碍串联的问题,我们轮流处理每个问题。
上下文在逐字节解码文件时,使用文件的前一个或两个字节为每个字节选择霍夫曼表。幸运的是,Brotli具有存储原始字节元块的能力。因此,我们总是将文件的前2个字节配置为存储在它自己的原始字节元块中,因此这两个字节总是正确地设置以下Huffman表上下文。在上面的可视示例中,如果我们盲目地串联编码块,我们将观察到开始元块的不同上下文-第一元块A的0000,然后第二元块A的0203(其中,根据其原始编码方式,它仍然应该是0000)。
位对齐和小数字节Brotli是位对齐的,而不是字节对齐的。如果不对整个文件进行解码,就不可能确定最后一个字节的已用位的分数。由于第一个字节必须使用原始字节元块作为霍夫曼表上下文的种子,我们很幸运,这些原始字节元块还需要与字节对齐,并且将始终以字节边界结束,从而同时解决了这个问题。
根据规范,字典基本上优先于文件,并通过获取流开始之前的字节来访问。因此,如果两个Brotli块是盲目连接的,那么第二个块中的字典读取将从第一个块中提取字节,而不是从字典中提取字节。例如,在上面的可视示例中,假设03在字典中,盲级联将导致第二元块C的错误向后距离。虽然字典被设计为加速查找,但在我们的测量中,我们发现停用字典在存储和传输方面仅额外花费约0.1%的额外文件大小。
最终元块将一个块标记为“最后”元块的位在文件中任意早,必须顺序扫描。在上面的示例中,请注意对于第二个编码块,我们将需要遍历到头来查找最后一个元块。最后一个元块不允许包含任何输出,所以我们只使用了最后一个原始字节元块之后的最后一个元块位码。这允许删除最后两个非零位,以便为后续文件让路。
因此,我们能够通过对压缩器进行以下小调整来构建可串联的Brotli流:
首先,我们更改了格式,从大小为2的未压缩原始字节元块开始,即文件流(和上下文)的前两个字节。这确保了正确选择霍夫曼上下文优先级,并且解压缩器可以预期字节对齐。
然后,我们将压缩器设置为忽略字典中的任何匹配,这样我们就不会意外引用不应该引用的任何内容
最后,我们确保最后一个元块为空(零元块),因此识别和丢弃最后一个元块(最后两位,后跟零)需要固定的时间。
有了这些限制,我们现在只需删除最后一对非零位,就可以在固定时间内串联文件。此外,我们添加了一个自定义的Broccoli标头,该标头对创建它的包的软件版本进行了编码,因此我们的块将是自描述的。Brotli允许包含注释的元数据元数据块,在我们的例子中还包含一个标题。因此,我们所有的Broccoli文件的前8个字节都有3个字节的幻数e19781。有关头字节的更深入解析,请参阅Golang西兰花头解析器。