位分割
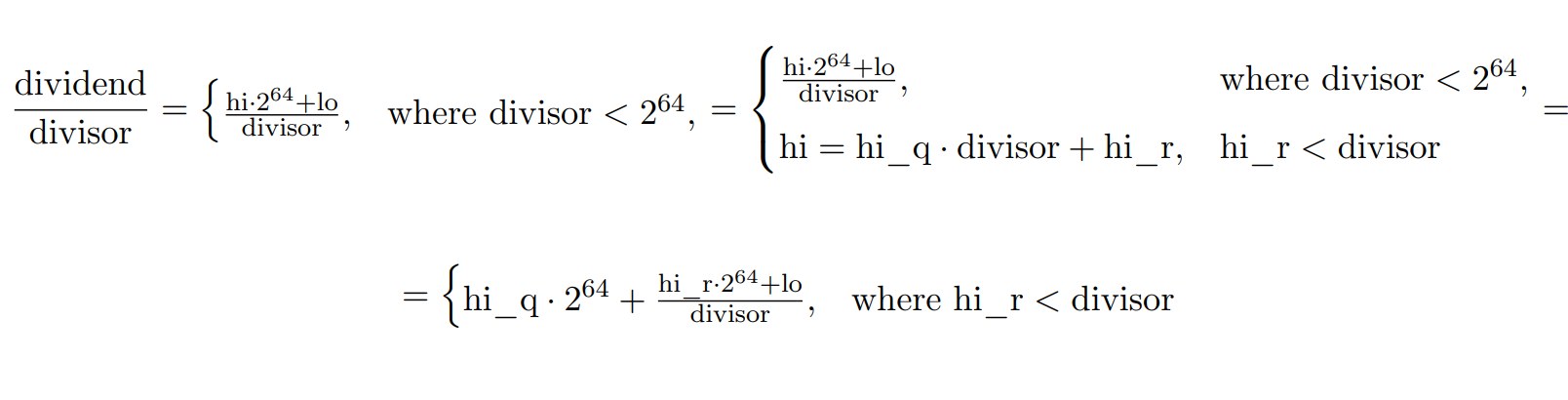
说到哈希,有时64位是不够的,例如,因为生日悖论-黑客可以在随机实体中迭代,并且可以证明他们将以一定的恒定概率发现冲突,即两个不同的对象将具有相同的哈希。大约是40亿个对象,以每台计算机目前的功率容量,这肯定是可以实现的。这就是为什么我们有时需要将散列的位数提高到至少128位。不幸的是,这是有代价的,因为平台和CPU本身不支持128位操作。
除法历来是CPU上最复杂的操作,所有指南都建议不惜一切代价避免除法。
在我的工作中,我面临着一个有趣的问题,那就是优化abseil库中的128位划分,以便在128位散列的帮助下跨存储桶拆分一些数据(由于一些乏味的历史原因,存储桶的数量并不固定)。我发现组织需要很长时间。ABSEIL在Intel(R)Xeon(R)W-2135 [email protected] GHz上进行的基准测试显示了一些可怕的结果。
基准时间(Ns)CPU(Ns)BM_DiVideClass128UniformDivisor 13.8 13.8//128位乘128位BM_DiVideClass128小除数168//128位乘64位。
150纳秒,用于将随机的128位数除以随机的64位数?听起来很疯狂。例如,x86-64 Skylake上的div指令需要76个周期(而且,AMD处理器的周期要少得多),除法大约需要20-22 ns。
实际上,由于流水线执行和除法都有自己的ALU,所以一切都稍微好一些,所以如果你在接下来的指令中除以一些东西并做一些其他的事情,你会得到更低的平均延迟。不过,128位除法不能比64位除法慢8倍。您可以在Agner Fog指令表中找到大多数现代x86 CPU的所有延迟。事实更为复杂,除法延迟甚至可能取决于给定的值。
即使编译器在除以某些常量时,也会尝试使用倒数(或者,与环中的倒数相同)值,然后将倒数和值相乘,然后进行一些移位。
总体而言,考虑到只有一些SIN,因为指令比除法成本更高,除法是CPU中最复杂的指令之一,在那里进行优化非常重要。我的具体情况或多或少是一般的,也许我将128位除以64位的频率要高一点。我们将对LLVM中的一般情况进行优化。
它调用__udivti3函数。让我们首先了解如何阅读这些函数。在运行时库中,函数的模式为:
QI:与最小可寻址单元一样宽的整数,通常是8位。HI:整数,是QI模式整数的两倍宽,通常是16位。SI:整数,是QI模式整数的4倍宽,通常是32位。DI:整数,是QI模式整数的8倍宽,通常是64位。SF:浮点值,和SI模式整数一样宽,通常是32位。DF:浮点值,和DI模式整数一样宽,通常是64位。
因此,udivti3是TI(128位)整数的无符号除法,最后的‘3’表示它有3个参数,包括返回值。此外,还有一个函数__udivmodti4,它计算除数和余数(除法和模运算),它有4个参数,包括返回值。这些函数是编译器默认提供的运行时库的一部分。例如,在GCC中,它是libgcc,在llvm中,它是编译器-RT,如果你有相应的工具链,它们几乎在每个程序中都是链接的。在LLVM中,__udivti3是__udivmodti4的简单别名。
__udivmodti4函数是在《PowerPC编译器编写指南》图3-40翻译的帮助下编写的。在这里看过之后,它看起来像是很久以前写的,从那时起情况就发生了变化。
首先,让我们想出一些简单的东西,比如我们从小就学习的Shift-Subtract算法。首先,如果除数>;被除数,那么商是零,余数是被除数,这不是一个有趣的例子。
算法很简单,我们根据数字的最高有效位对齐,如果被除数大于除数,则将输出减去并加1,然后移位1并重复。可以看到某些类型的动画,如下所示:
对于128位除法,在for循环中最多需要128次迭代。实际上,LLVM for循环中的实现是一个后备方案,我们看到它需要150+ns才能完成,因为它需要移位许多寄存器,因为128位数字表示为两个寄存器。
现在,让我们深入研究体系结构特性。我注意到,当编译器生成divq指令时,它释放了rdx寄存器。
DIVQ指令提供从[%rdx]:[%rax]除以S的128位除法。商存储在%rax中,余数存储在%rdx中。在C/C++中对内联ASM进行了一些实验之后,我发现如果结果不适合64位,就会引发SIGFPE。见:
编译器不会在128位除法中使用此指令,因为它们不能确定结果是否适合64位。但是,如果128位数字的高64位小于除数,则结果适合64位,我们可以使用此指令。由于编译器出于自身原因不会生成divq指令,我们将使用x86-64的内联ASM。
如果最高值不小于除数,该怎么办?正确的答案是使用2个除法,因为。
所以,我们可以先把hi除以除数,然后再除以{hi_r,lo},保证hi_r小于除数,因此结果小于。我们会得到一些类似的东西。
接下来有多个选择要做,但是我们知道被除数和被除数的高位寄存器中都至少有一位,移位-减法算法最多有64次迭代。在移位-减法算法中,由于保证商的大小为64位,因此可以只使用所得商的低位寄存器,节省更多的移位。这就是均匀除数稍有改善的原因。
在Shift-Subtract算法中要做的另一个优化是删除for循环中的分支(仔细阅读,这应该是可以理解的)。
最后,我认为这是将128位除以128位数的最佳算法之一。从统计上看,除数为64位的情况是值得优化的,说明了对除数的高位寄存器进行额外检查有其自身的优势和对不变量的扩展。现在让我们看看其他库在这种情况下的表现。
LibDivide是一个以快速除法为目标的小型库,例如,如果你多次除以某个固定的数字,有一些技术可以预先计算倒数,然后再乘以它。LibDivide为此类优化提供了一个非常好的接口。尽管如此,它在128位除法方面仍有一些优化。例如,函数libDivide_128_div_128_to_64计算128位数字除以128位数字(如果结果适合64位)。在两个数字都大于或等于它的情况下,执行他们从黑客欢乐书中获取的以下算法:
使用当除数是128位结果时产生64位结果的指令,我们可以计算。
因为IS的最大值和IS的最小值都是,所以不能溢出。现在让我们展示一下。
现在我们想要展示这一点。是最大的当分子中的余数尽可能大时,它可以达到。因为…的定义。分母中的最小值是。怪不得。
。当n从0迭代到63时,我们可以得出这样的结论。所以我们要么得到了正确的值,要么得到了正确的正1。算法中的其他所有内容都只是对要选择的结果的修正。
GMP库是用于长算法的标准GNU库。它们还支持128位乘以64位除法,在我的基准测试中,以下代码可以正常工作。
它将两个肢体除以uint64_t并提供结果。不幸的是,延迟比预想的要高很多,也不能工作。
最后,我尝试了几种128位除法,得出了流行的替代方法中速度最快的方法。以下是基准测试的完整代码,尽管安装起来相当困难,也许稍后我会提供一个简单的安装版本。最终的基准是。
基准时间(Ns)CPU(ns)----BM_DivideClass128UniformDivisor<;absl::uint128>;13.7 13.7BM_RemainderClass128UniformDivisor<;absl::uint128>;14.0 14.0 BM_DivideClass128SmallDivisor<;absl::uint128>;169 BM_RemainderClass128SmallDivisor<;absl::uint128>;153153 BM_DivideClass128UniformDivisor<;LLVMDivision>;12.6 12.6 BM_RemainderClass128UniformDivisor<;LLVMDivision>;12.3 12.3 BM_DivideClass128SmallDivisor<;LLVMDivision>;145 BM_RemainderClass128SmallDivisor<;LLVMDivision>;140 140**BM_DivideClass128UniformDivisor<;MyDivision1>;11.6 11.6****BM_RemainderClass128UniformDivisor<;MyDivision1>;10.7 10.7****BM_DivideClass128SmallDivisor<;MyDivision1>;25.5 25.5****BM_RemainderClass128SmallDivisor<;MyDivision1>;26.2 26.2**BM_DivideClass128UniformDivisor<;MyDivision2>;12.7 12.7 BM_RemainderClass128UniformDivisor<;MyDivision2>;12.8 12.8 BM_DivideClass128SmallDivisor<;MyDivision2>;36.9 36.9 BM_RemainderClass128SmallDivisor<;MyDivision2>;37.0 37.1 BM_DivideClass128UniformDivisor<;GmpDivision>;11.5 11.5 BM_RemainderClass128UniformDivisor<;GmpDivision>;10.7 BM_DiVideClass128SmallDivisor<;47.5 47.5 BM_RemainderClass128SmallDivisor<;GmpDivision>;47.8 47.8 BM_DivideClass128UniformDivisor<;LibDivideDivision>;26.3 26.3 BM_RemainderClass128UniformDivisor<;LibDivideDivision>;26.2 26.2 BM_DivideClass128SmallDivisor<;LibDivideDivision>;25.8 25.8 BM_RemainderClass128SmallDivisor<;LibDivideDivision>;26.3 26.3
MyDivision1将在LLVM中上行,MyDivision2将成为所有非x86-64平台的默认版本,它也有稳定的延迟,比之前的版本要好得多。