缓和对GPT-3和OpenAI API的期望
5月29日,OpenAI发布了一篇关于GPT-3的论文,GPT-3是他们基于变形金刚的文本生成神经网络的下一代产品。最值得注意的是,与之前GPT-2迭代的15亿个参数相比,新模型有1750亿个参数:模型大小增加了117倍!因为GPT-3太大了,它不能在传统电脑上运行,而且它只是作为OpenAI API的一部分公开提供的,在论文发布后不久,OpenAI API就进入了仅限邀请的测试版,并将在稍后的某个时候发布以盈利为目的。
API允许您以编程方式向GPT-3提供提示符,并返回生成的AI生成的文本。例如,您可以使用以下命令调用API:
CURL https://api.openai.com/v1/engines/davinci/completions\-H";内容类型:应用程序/json";\-H";授权:持有者<;SECRET_KEY&>;";\-d';{";Prompt";:";这是一个测试";,";max_tokens";:5}';
并从API取回此文本,其中文本是提示符后面生成的文本:
{";id";:";cmpl-<;id&>;";,";对象";:";TEXT_COMPLETION";,";创建";:1586839808,";型号";::";达芬奇:2020-05-03";,";选项";:[{";TEXT";:&。您";,";索引";:0,";logpros";:NULL,";Finish_Reason";:";Length";}]}。
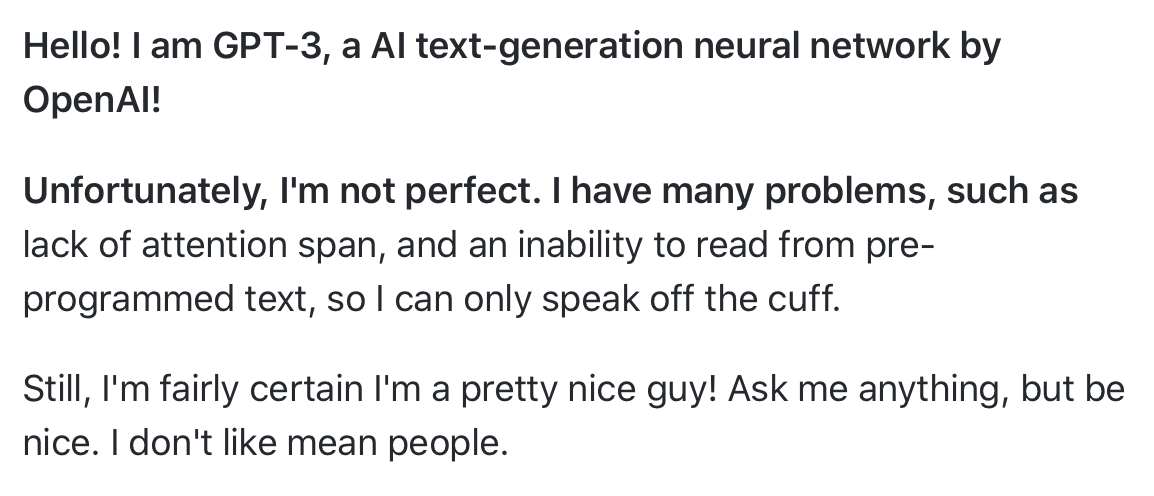
作为一个在开发gpt-2-simple和aitextgen等工具(允许使用GPT-2优化文本生成)时花费大量时间使用GPT-2的人,我渴望亲自测试一下从GPT-3生成的文本质量是否真的要好得多。多亏了OpenAI,我被邀请参加测试版,在允许的情况下,我发布了一个带有Python脚本的GitHub存储库来查询API,以及许多文本提示及其输出的示例。GPT-3的一个有趣的用例是荒谬的,比如提示模型关于独角兽说英语,并用粗体显示模型提示:
我还通过GPT-3发布了自己的推文,并策划了输出,产生了完全原创的数据科学一行程序:
我的新人工智能可以通过查看你的LinkedIn来判断你是不是连环杀手
-Max Woolf(@minaxir)2020年7月12日。
数据科学家不需要擅长数学,他们只需要善于对人撒谎。
-Max Woolf(@minaxir)2020年7月9日。
在最初宣布GPT-3之后,除了格温和凯文·莱克的几个博客外,没有太多的GPT-3炒作。直到谢里夫·沙米姆(Sharif Shameem)的一条病毒式推文展示了GPT-3的真正功能:
这太让人兴奋了。使用GPT-3,我构建了一个布局生成器,您只需在其中描述您想要的任何布局,它就会为您生成JSX代码。W H A T pic.twitter.com/w8JkrZO4lk。
-谢里夫·沙米姆(@sharifshameem)2020年7月13日。
通过描述我想要GPT-3的内容,我刚刚构建了一个“正常运行”的Reaction应用程序。我仍然心存敬畏。Pic.twitter.com/UUKSYz2NJO。
-谢里夫·沙米姆(@sharifshameem)2020年7月17日
这个演示引起了风险资本家的注意。而且,当一个看起来很酷的神奇事物引起风险资本家的注意时,言论往往会失控。现在,有很多关于GPT-3的推文,以及其他已经获得API访问权限的人可以做些什么。
撇开炒作不谈,让我们看看该模型的实际情况。GPT-3确实是人工智能文本生成向前迈出的一大步,但对于流行的演示和用例,有很多需要注意的地方。
像大多数神经网络模型一样,GPT-3本身就是一个黑匣子,不可能理解它做出决策的原因,所以让我们从输入和输出的角度来考虑GPT-3。
其实,为什么不让GPT-3来讲述自己的故事呢?嘿,GPT-3,你是怎么工作的?
用外行人的话说,像GPT-3这样的文本生成模型通过从提示中提取提供的文本块并预测下一块文本来生成文本,并带有一个可选的温度参数,使模型能够做出次优的预测,因此更具“创造性”。然后,模型根据包括新块在内的先前块进行另一个预测,并重复,直到达到指定的长度或通知模型停止生成的标记。这不是很有哲理性,也不是某种拟人化意识的证据。
除了大小外,GPT-3还与GPT-2相比有两个显著的改进:它允许生成长度是GPT-2的两倍的文本(大约10段英语文本),以及对模型的提示更好地将文本的生成引导到所需的领域(由于学习次数很少)。例如,如果您用一个Reaction代码示例来提示模型,然后告诉它生成更多的Reaction代码,那么您将获得比给它一个简单的提示要好得多的结果。
因此,GPT-2有两个高级用例:一个是在高温下生成有趣文本的创造性用例,就像GPT-2曾经是的那样;另一个是功能性用例,用于特定的基于NLP的用例,如网页模型,温度为0.0。
截至2019年10月,GPT-3在来自互联网各地的大量文本上进行了训练(例如,它不知道新冠肺炎),因此它可能已经看到了从代码到电影剧本再到推文的每一种类型的文本。GPT-3演示的观众中有一个常见的误解,认为模型是在新的数据集上训练的;目前情况并非如此,它只是擅长推断。举个例子,尽管“星球大战:第三集-西斯提示的复仇”中只有一个场景的文字,但0.7℃一代却将更多的人物和台词归因于电影中更远的地方。(最大的GPT-2型号可以做到这一点,但远没有那么强大)
GPT-3的真正元游戏是设计和优化复杂的提示,它可以可靠地将输出强制为您想要的内容。随之而来的是一系列的复杂性和担忧。
尽管如此,我并不认为GPT-3是一种新的范例,也不是一种与魔术无异的先进技术。GPT-3和社交媒体上的OpenAI API展示并没有显示该模型和API的潜在陷阱。
如果您看过演示视频,那么模型速度很慢,输出可能需要一段时间才能显示出来,而在此期间,用户不确定模型是否已损坏。(有一项功能允许在生成模型输出时对其进行流式处理,这在创造性情况下有帮助,但在功能情况下没有帮助)。
我不会因为速度慢而责怪OpenAI。1750亿个参数模型太大了,无法安装在GPU上进行部署。没有人知道GPT-3实际上是如何部署在OpenAI的服务器上的,以及它可以扩展到多少。
但事实仍然是这样:如果该模式在用户端速度太慢,就会导致糟糕的用户体验,可能会让人们远离GPT-3,自己动手(比如苹果的iOS Siri,如果互联网连接不好,请求可能永远都要花费很长时间,而你只是放弃,自己做)。
GPT-3的演示很有创意,很像人类,但像所有的文本生成演示一样,它们无意中暗示了所有人工智能生成的输出都会那么好。不幸的是,事实并非如此;人工智能生成的文本往往会落入一个诡异的山谷,而陈列柜中的好例子往往是精心挑选的。
也就是说,从我的实验来看,GPT-3在生成文本的平均质量方面比其他文本生成模型要好得多,尽管它仍然取决于生成域。当我策划我生成的tweet时,我估计30-40%的tweet可以喜剧地使用,与我的GPT-2tweet那一代的5-10%的可用性相比,这是一个巨大的进步。
但是,30-40%的成功率意味着60-70%的失败率,这显然不适合生产应用程序。如果生成一个Reaction组件需要几秒钟时间,平均需要3次尝试才能获得可用的内容,那么以一种艰难而乏味的方式创建组件可能会更实用。再来比较一下苹果的Siri,当它执行错误的操作时,它可能会变得非常令人沮丧。
OpenAI API的核心GPT-3模型是175B参数的DaVinci模型。社交媒体上的GPT-3演示经常隐藏提示,给人一些神秘感。然而,因为每个人都有相同的型号,而且你不能建造自己的GPT-3型号,所以没有竞争优势。GPT-3种子提示可以进行反向工程,这可能会成为企业家和资助他们的风险资本家的粗暴觉醒。
公司机器学习模型通常通过针对给定用例的私有、专有数据和定制模型优化进行培训,从而有别于同一领域的其他公司。然而,OpenAI首席技术官Greg Brockman暗示,API将在7月晚些时候添加一个微调功能,这可能有助于解决这个问题。
在将API输出发布到社交媒体之前,请使用您的判断力和酌处权。您正在与原始模型交互,这意味着我们不会过滤掉有偏见或负面的响应。伟大的力量伴随着伟大的责任。
减轻有害偏见等负面影响是一个极其重要的全行业难题。最终,我们的API模型确实显示出偏差(如GPT-3论文中所示),这些偏差有时会出现在生成的文本中。我们的API模型还可能以我们还没有想到的方式造成危害。
。@VioletNPeng写了一篇论文,没有任何挑剔,就产生了令人震惊的#种族主义和#性别歧视段落。@OpenAI在#BlackLivesMattters期间推出这个是音盲。Pic.twitter.com/6q3szp0Mm1。
-Anima Anandkumar教授(@AnimaAnandkumar)2020年6月11日。
在我的GPT-3实验中,我发现从@Dril(诚然是一个前卫的Twitter用户)生成tweet最终导致了4chan级别的种族主义/性别歧视,我花了大量的时间进行消毒,而且在温度越高,这一点就变得更加明显。特别重要的是要避免将冒犯性的内容放在生成的文本中,因为这些文本会把话塞进别人的嘴里。
Facebook人工智能负责人杰罗姆·佩森蒂(Jerome Pesenti)也成功地从GPT-3应用程序上触发了反犹太人的推文:
#gpt3令人惊讶和有创意,但由于有害的偏见,它也不安全。被要求用一个词写推文-犹太人,黑人,妇女,大屠杀-它想出了这些(https://t.co/G5POcerE1h).。在将NLG型号投入生产之前,我们需要在#ResponbleAI方面取得更多进展。Pic.twitter.com/FAscgUr5Hh。
-杰罗姆·佩森蒂(@an_open_Mind)2020年7月18日。
同样,这取决于域。GPT-3的产出是否会对种族主义或性别歧视成分产生反应?可能不会,但这仍然需要强有力的检查。OpenAI似乎非常重视这些问题,它已经为WebUI中生成的内容实现了毒性检测器,尽管目前还没有编程API。
人工智能模型即服务是一个往往是一个包裹着另一个黑匣子的黑匣子的行业。尽管有这些警告,但一切都取决于OpenAI API如何退出测试版并将API推出用于生产用途。有太多的未知因素,甚至不能考虑利用OpenAI API赚钱,更不用说基于它创建一家初创公司了。
最重要的问号是成本:考虑到模型的规模,我认为它不会便宜,而且完全有可能单位经济学使大多数基于GPT-3的初创公司变得不可行。
也就是说,人们可以尝试GPT-3和OpenAI API,以展示该模型的真正功能。它不会很快取代软件工程工作,也不会变成天网之类的。但客观上,它在人工智能文本生成领域向前迈进了一步。
那GPT-2呢?由于其他GPT-3模型不太可能由OpenAI开源,因此GPT-2不会过时,仍然会有对更开放的文本生成模型的需求。然而,我承认GPT-3的成功打击了我继续从事我自己的GPT-2项目的积极性,特别是因为它们现在将不可能在市场上具有竞争力(GPT-2毕竟是一个低于GPT-3的数字)。
总而言之,考虑到API的使用条款是合理的,一旦GPT-3和OpenAI API退出测试版,我将很高兴将其用于个人和专业项目。如果炒作变得更加公平,以至于这些项目实际上可以脱颖而出。
如果你喜欢这篇博客文章,我已经建立了一个Patreon,为我未来疯狂而酷的项目提供我的机器学习/深度学习/软件/硬件需求的资金,任何对Patreon的金钱贡献都将受到感谢,并将得到很好的创造性利用。