在锈迹斑斑的情况下重写Fortran软件
TL;DR:重写并不总是糟糕的,Amdahl定律很重要,在执行许多简单的双精度数学运算时,内存带宽是一个潜在的瓶颈。
作为大学一年级本科生研究助理计划的一部分,我的任务是对圣安德鲁斯大学涡旋动力学研究小组的David Dritschel博士用FORTRAN编写的一个浅水模拟软件进行并行化,并由Alexander Konovalov博士监督。还有一些次要目标,比如改进测试基础设施、设置CI/CD、估计进度以及允许暂停和恢复计算。
预告:我在这个项目中基本上没有领域知识(流体动力学模拟不是那种可以在周末赶上研究水平的主题),所以我是从纯软件工程的角度来研究这个项目的。至于我的铁锈经历,从2016年开始,我就一直在用它做个人项目,高中毕业后,我在柏林的一家初创公司担任了一年的铁锈软件工程师。
这并不是一个很难理解的概念,不是吗?对于为什么不应该重写遗留软件,没有太多的模棱两可和清晰的推理可循。嗯,我读了那些比我经验丰富、知识渊博得多的人写的文章,我想:
撇开玩笑不谈,在某些情况下,重新实现是一个合理的选择,我确实有几个因素来支持我。
毫无疑问,Fortran速度非常快,非常适合使用经过数十年优化的编译器和调试工具解决HPC问题,但它确实缺乏某些功能,即内存安全、线程安全、数据竞争保证和符合人体工程学的GPU/CLI/TUI库。
我用C和Rust编写了并行软件,Rust提供的内存安全保证和与Rayon的轻松并行化与我使用OpenMP的糟糕体验形成了鲜明对比。将.iter()替换为.par_iter(),并让编译器自动为任何不是线程安全的代码抛出错误,与添加OpenMP指令标记(设计为对不符合OpenMP的FORTRAN编译器隐藏)并手动确定线程和内存安全性相比,这是令人惊叹的。这里似乎是一个很好的地方,可以提到“微软每年分配给CVE的大约70%的漏洞仍然是内存安全问题”。
最初人们认为GPU可以用来加速计算,~Rust的(虽然不成熟)生态系统也比那些为FORTRAN~EDIT提供的生态系统闪耀着光芒的另一个地方:完全不是这样的,FORTRAN的GPU加速库非常成熟,可以投入生产。此外,当涉及到额外需求时,与Rust中提供的库相比,用FORTRAN构建ncurses接口并不完全符合人体工程学。我花了一些时间通读原始实现,并尝试了一些基本的并行化,但收效甚微,因为在没有跨多个模块的快照测试的情况下,很难在长时间的执行中诊断出小错误。
不仅有几个“拉动”因素,而且还缺少不应该重写的典型原因:我是作为一个人团队工作的,软件已经完成,因此不需要再次修改,它相对较小,因此可以在几个月内(兼职)重写,并且不是活动的业务组件,因此与原始实现的正常运行时间和维护无关。
考虑到这一切,我决定用Rust重写会比用FORTRAN更快地进行并行化和添加功能,而且在主管的同意下,我可以开始工作了。
将编译语言中的现有代码库相对简单地翻译成Rust是一个值得注意的好处,这是因为结合了C2Rust等软件来执行C源代码到Rust的自动转换,bindgen用于自动生成FFI绑定,以及Cargo作为Rust项目的一部分用其他语言编译代码的能力。虽然有很多以这种方式成功迁移到Rust的大型项目的例子,但我面临的问题是它需要两个步骤的过程,首先从FORTRAN转换到C,然后从C转换到Rust。我假设生成的代码可远程解析的可能性非常低,我甚至无法使用两个最流行的FORTRAN到C转换工具。
因为最初的实现总共只有6,000行,所以我决定使用手动翻译。这涉及到从模块树的底部开始,使用快速傅立叶变换例程,然后向上工作。我通过在例程的开头和结尾处插入一小段FORTRAN来转储状态,然后将其用于Rust实现的快照测试,从而使我的过程变得简单。这就产生了一个彻底的、健壮的测试套件,这在优化期间是无价的。在翻译阶段,我真的只做了一个糟糕的设计决定(请不要通读GIT历史来确认这个😅),它认为嵌套的VEC从一开始就比使用ndarray更容易。这是一个糟糕的决策™️,浪费了如此多的时间,不仅在极低的执行速度上降低了货物测试的速度,而且还显著增加了开发时间。我将替换如下语句。
//0..x{for j in 0..y{a[i][j]=a[i][j]*b[i][j]}。
显然,可以跳过中间步骤,而更直接的翻译是可能的。我编写了一个正则表达式,将FORTRAN数组索引语法(array(x,y,z))替换为Rust(array[x][y][z])中的嵌套VEC,而ndarray语法(array[[x,y,z]])的转换要简单得多。如果这个决定还不够糟糕,当ndarray具有内置的FORTRAN形状和步长预置时,我还浪费时间编写了几个函数来使用FORTRAN内存布局在字节片和嵌套VEC之间进行转换。
测试过程中出现的一个问题是,由于浮点数学中积累的小错误,操作系统和硬件配置之间的结果会略有不同,这使得出色的快照测试工具Insta不合适。取而代之的是,ndarray的serde和近似功能标志用于从磁盘读取序列化数组,以便在测试期间进行大致比较,该测试一直运行良好。
从根本上说,这个问题可能不会被描述为“令人尴尬的平行”,这是项目中所做的假设(早期的讨论涉及对大学集群提高100倍的预期)。理想情况下,我们希望大量独立计算在少量数据上运行,这使得在线程、GPU和潜在的不同机器之间分配工作变得很容易,但不幸的是,我了解到这个问题与理想相去甚远。
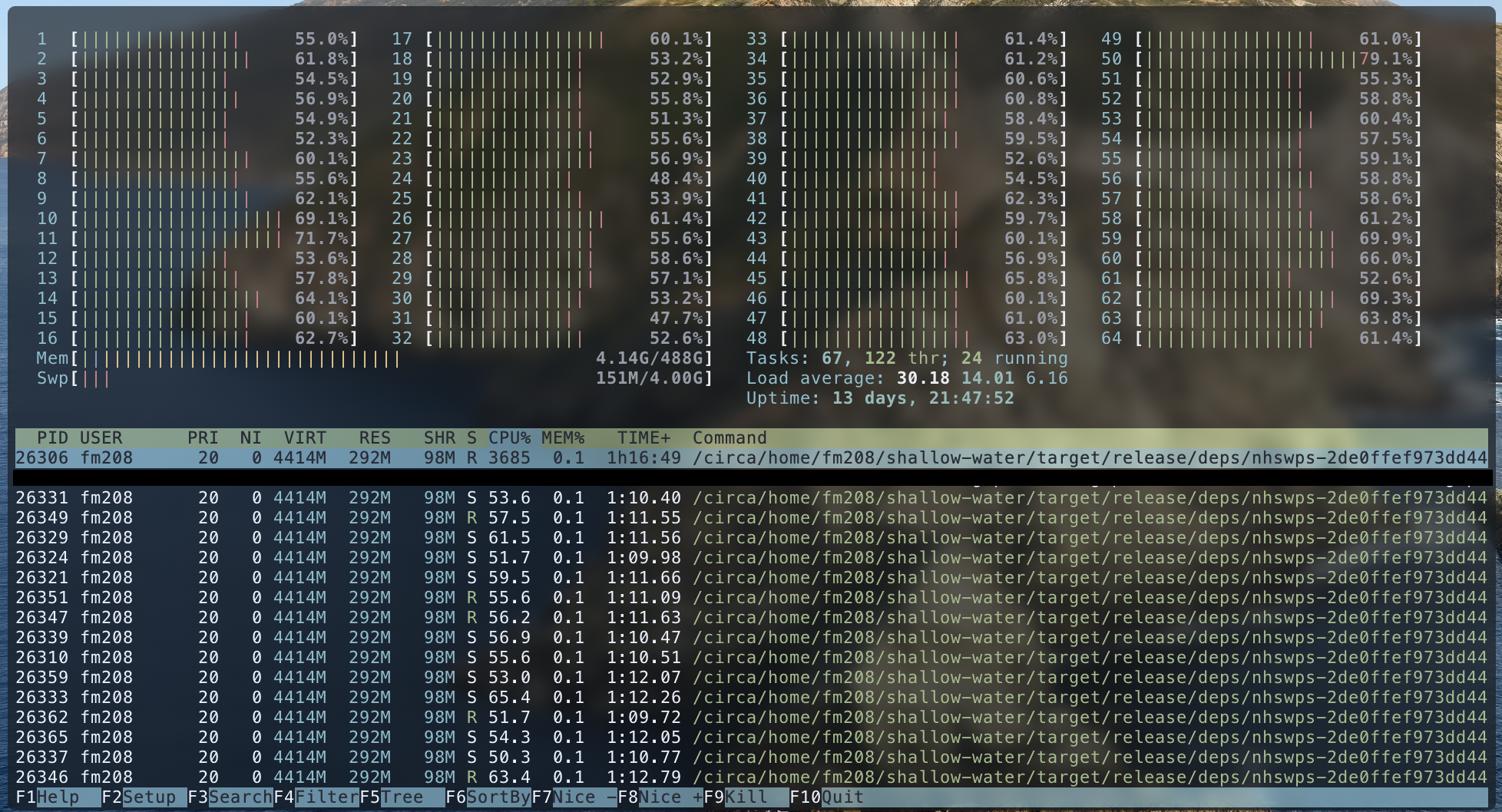
最外层的循环随着时间前进,因此是严格顺序的,并且在程序的主要函数(src/nhswps/Advance.rs:Advance)中,很大一部分被迭代两次,也是严格顺序的。其他一些较低级别的函数在各个层上执行操作,因此可以完全并行化,但这些通常不是非常复杂的函数,因此在返回到顺序执行之前很快完成。Amdahl定律在这里生效,描述了即使所有可以并行化的东西都是并行的,我们所能实现的扩展也是有根本限制的。
在整个程序中,对二维和三维数组执行了几种类型的操作。物理和光谱之间的转换很常见,涉及调用傅立叶变换函数和交换轴。除此之外,许多操作都是数组之间的简单加法、减法和乘法,有时还包括常量。这样做的结果是,这些简单的操作是在一些非常大量的数据上执行的,我认为这会导致内存带宽瓶颈。这一假设解释了为什么SIMD没有提高性能,并且并行化没有显著提高性能。执行浮点加法或MUL指令只需要几个周期,因此即使在每秒数十千兆字节的内存带宽下,也不足以保持CPU的“供给”。使用AVX-2指令执行操作不会提高性能,因为即使现在可以同时对几个浮点执行相同的操作,限制仍然是从存储器中读取它们的速度。在多线程上下文中,它稍微复杂一些,因为性能有所提高;可能是因为多线程能够增加从内存读取的数据量。该程序对高速缓存也非常不友好,在读取新数据之前,只需执行简单、快速的操作即可读取大量数据。几个千兆字节的大小,即使是单独的层也无法驻留在芯片上的高速缓存中。我不确定如何收集我的假设的证据,但我相信它解释了我在整个项目中目睹的许多行为。
在项目开始时,也有一些希望可以使用GPU,但有两个主要原因是它们不适合使用。
首先,没有配备大量VRAM(128 GB+)的GPU~编辑:我错了,商业游戏和工作站GPU没有那么大,但有很多数据中心选项,比如A100。还有Radeon Pro SSG,这是一款非常有趣的产品,但SSD存储的内存带宽完全不够。
第二个原因也是问题性质的问题。令人惊讶的是,GPU在类似于图形渲染的计算方面非常出色,例如对许多数据应用相同的转换。~浅水在热路径中有几个FFT例程,它们读取和写入数组中的单个元素,这在GPU上执行时性能不佳~编辑:是的,我在这一点上也是错误的,我应该说我是如何被告知FFT例程被稍微修改的,一般的FFT库不能工作的。
我根据不同的输入大小对两个版本进行了基准测试,并绘制了结果,如上图所示。对于30K和15M元素之间的输入,铁锈版本的速度更快(高达50%),外部则被FORTRAN版本取代。
我猜想,由于线程开销,FORTRAN在小输入上更快,但在大输入上更快,因为线程之间争用高速缓存线和内存带宽。
我决定在Rust中重写,尽管重写遗留代码很少是一个好主意,因为编译时安全检查将节省时间,而且广泛的库生态系统将使测试、实现GPU加速和用户界面改进变得更容易和更快。有几次,编译器阻止我编写一些我最初认为是安全的线程不安全的代码,从而为我节省了大量的调试工作。
不幸的是,这一假设没有考虑到问题可能不会像分配项目时最初认为的那样并行或服从GPU加速,但总的来说,尽管如此,我对实现的性能改进感到高兴。



