正则表达式拒绝服务(REDOS)小抄
这篇文章旨在作为一个“技术双页页”来总结一个称为基于Regex的拒绝服务(AKA Regex dos,redos)的安全漏洞。有各种各样关于redos的文章,但我不知道有什么好的一站式商店能对这个主题的各个方面进行更高层次的处理。我在结尾处加入了更详细治疗的链接。
正则表达式(Regex)是您的工程团队用来操作字符串的工具。他们可能会使用它来对非结构化输入施加某种顺序,例如在处理用户数据或处理日志文件时。
正则表达式是字符串的模式语言。您可以使用正则表达式来询问类似“这个字符串看起来像电子邮件吗?”这样的问题。
正则表达式内置于大多数编程语言中,并由获取字符串和正则表达式(字符串模式)并决定字符串是否与模式匹配的正则表达式引擎进行计算。
REDOS是一个性能问题。它可能会通过外部拒绝服务攻击或“意外但非恶意”因素的组合导致服务中断(请参阅堆栈溢出时的错误汇合)。
redos的核心前提是某些正则表达式-我称之为这些redos正则表达式-可能需要非常长的时间来匹配(或不匹配)某些字符串。如果有问题的输入是可信的,这将是很好的,但正则表达式通常应用于用户可控制的输入,例如,用于确认Web表单实际上包含电子邮件地址和电话号码。
如此长的匹配时间可能会将计算资源(CPU时间、工作线程)从合法客户端转移到少数几个长期运行的正则表达式匹配上。这可能会在两个方面导致问题:
如果攻击者可以识别您的正则表达式运行缓慢的输入,他们就可以向您发送这些输入并关闭您的服务(或增加您的云开销)。
如果您的正则表达式应用于新的输入类(例如,您的服务每天接收的流量增加10倍,或者您在一个新的国家/地区部署您的软件),新的输入可能会发现以前隐藏的性能问题,并且同样会影响您的服务。
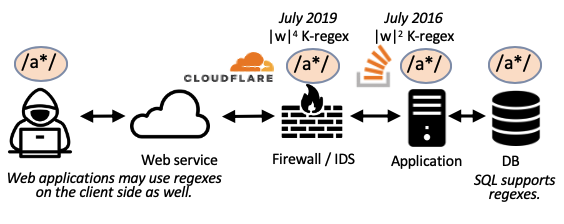
正则表达式在整个系统堆栈中使用(见图),因此整个系统堆栈中的软件都可能是重做的来源。
您对不受信任的输入使用redos正则表达式。我将在下一节讨论这个问题。
您的正则表达式引擎使用速度较慢的正则表达式匹配算法。大多数编程语言运行时内置的正则表达式引擎就是这种情况-包括Java、JavaScript(各种风格)和Node.js、C#/.NET、Ruby、Python、Perl和PHP。为了安全起见,Go和Rust都使用快速的正则表达式引擎,Google的RE2库也很快。
您的正则表达式引擎没有资源使用限制。一些正则表达式引擎提供了限制,包括Perl、PHP和C#/.NET,其中只有.NET正则表达式引擎提供的基于时间的限制是有用的。如果您在.NET中使用正则表达式,请使用带超时的API!
如果您操作Web服务器,如果您使用的是Node.js或其他事件驱动的框架,这些框架允许一个昂贵的请求阻止其他请求,那么您应该特别小心。在这里和这里阅读更多关于这方面的信息。
我在这里用一组优秀的自动检查器维护一个项目。我还维护了Safe-regex项目,尽管目前它只检测到一小部分有问题的regex。
如果希望手动查找redos正则表达式,基本的经验法则是避免模棱两可-在这种情况下,正则表达式引擎可能会做出两个不同的选择,并最终在同一点结束(我将在下面的附录中介绍这一点,请参阅标题“是什么使redos正则表达式变得如此缓慢?”)。
歧义通常是由于OR和量词(*、+、{5,10}等)造成的。有些歧义比其他的更糟糕--(a|a)是模棱两可的,但只有一点点。(a|a)*是指数模棱两可的,因为每增加一个a,路径的数量就翻一番。如需图解,请参阅图片。
坦率地说,你的眼睛很难做到这一点。我已经研究了数百个redos正则表达式,但对于特别棘手的示例仍然有问题。但这里有一些经验法则:
嵌套的量词可能是指数级危险的-例如(a*)*。检查您是否可以“绕回”内部量词,取而代之的是外部量词。
量化析取可能是指数级危险的,例如(a|a)*。检查通过析取的两个不同路径是否可以匹配任何字符串。
连接的量词可以是多项式危险的-例如ABC。*定义*。某个字符串是否可以通过第一个限定符、中间模式和下一个限定符进行匹配?这些是最常见的redos正则表达式类型,因为许多正则表达式包含.*或[\s\S]*(即,通用限定符)。每个额外的可达量词都会使成本成倍增加。
作为前一种情况的特例,如果您正在执行部分匹配,例如“在此自由格式文本中搜索电子邮件地址”,则正则表达式引擎会添加一个隐式。*?到您的正则表达式的开头。
您可以将redos正则表达式转换为安全的正则表达式或替代字符串逻辑。
如果替代字符串逻辑是可行的,那么这是一个很好的方法。不过,有些API只接受正则表达式,因此您可能需要将您的正则表达式重构为安全的变体。
一般来说,您的目标是消除正则表达式中有问题的歧义。
接下来,我要消除歧义。这可以通过几种方式来实现。例如,您可以将您要量化的内容更改为类似于[^@]+@.+的电子邮件regex.+@.+。然后,中间的“@”成为两个量词之间的守卫。或者您可以转换可选性,例如将数字regex\d+\.?\d+转换为等价的\d+(\.\d+)?如果在代码中使用捕获组,则可能需要引入多层正则表达式,例如,先是粗粒度的正则表达式,然后是细粒度的正则表达式。
然后,我确认之前有问题的输入现在是安全的(例如,使用Regex101),并检查我没有在过程中添加新的多义性。
最后,我根据我的输入测试套件检查正则表达式,以确认我没有更改它的字符串语言(或者至少没有以有问题的方式更改)。
可以应用的最简单的清理方法是在将输入提供给正则表达式之前测试输入的长度。如果合法输入较短,则在正则表达式检查之前而不是之后强制实施长度限制。这有助于避免通过多项式行为(例如abc.*定义*的常见模式)进行重做。
有更复杂的消毒剂,但我不相信自己能正确使用。如果合法输入很长,请不要遵循此方法。
目前,使用最广泛的快速正则表达式引擎是RussCox/Google的RE2regex引擎。它具有大多数编程语言的绑定。您可以将其作为依赖项引入,并在那里计算您的正则表达式查询。
某些正则表达式可能表现出略有不同的匹配行为。这可能很难检测到,所以这是增强您的测试套件的好时机。您也可以尝试像微软的Rex项目这样的输入生成器(这里有一个输入生成器集合)。
如果您使用的是C#/.NET,最佳实践是始终对您的正则表达式匹配使用基于超时的API。
在其他编程语言中,您可以使用线程和计时器“滚动您自己的”版本。
如果你有建网站的经验,想帮忙的话,请给我写信。我有很多想法。
以下是从不同角度收集的有关REDOS的资源:案例研究、学术研究和其他面向实践者的帖子。
CloudFlare在2019年发生了一次停机。根本原因是失控的正则表达式评估。他们的尸检在这里。
堆栈溢出在2016年发生了中断,也是由失控的正则表达式造成的。他们的尸检在这里。
Atom文本编辑器在2016年出现了失控的正则表达式。这不是redos(没有拒绝其他客户端的服务),但是可以在这里找到一个有趣的“开发人员视角”。
按照相反的时间顺序,以下是关于redos的最相关的研究论文。我已经包括了博客帖子的链接,源代码等,如果有的话。
论正则表达式拒绝服务的影响和失败。(戴维斯2020)-这是我的博士论文。它的目的是作为REDOS的权威参考。背景部分描述了我所知道的所有文献(包括下面没有提到的一些早期工作)。论文,视频。
雷克斯是很难的。(Michael等人,ASE‘19)-围绕正则表达式的软件工程实践。在第8节中,他们报告说大多数软件工程师不知道redos。总结,全文。
为什么Regex不是Langua Franca?(Davis等人,ESEC/FSE‘19)-第7节包括按编程语言细分的正则表达式性能。总结,全文。
正则表达式拒绝服务(REDOS)在实践中的影响。(Davis等人,ESEC/FSE‘18)-测量超线性正则表达式使用的程度,加上识别启发式和修复策略。摘要、全文、探测器集合。
救援:精心设计正则表达式DoS攻击。(沈等人,ASE‘18)-识别超线性正则表达式的动态方法。满纸,探测器。
JavaScript和Node.js的时间感。(Davis等人,SECURITY‘18)-讨论对Node.js web服务特别有问题的相关威胁中的redos。摘要,论文+视频+幻灯片。
静态检测使用正则表达式的程序中的DoS漏洞。(Wustholz等人,TACAS‘17)-类似于Weideman等人,他们基于自动机分析描述了REDOS的充要条件。它们包括针对Java程序的端到端利用漏洞检测。整张纸,探测器罐子文件。
利用NFA的模糊性分析回溯正则表达式匹配器的匹配时间行为。(Weideman等,CIAA‘16)-基于自动机分析的REDOS的充要条件。全文,魏德曼的论文,探测器源代码。
正则表达式匹配可以简单而快速(但在JAVA、PERL、PHP、Python、Ruby、…中速度较慢)。。(Cox 2007)-反对回溯正则表达式引擎的温和争论,支持汤普森匹配算法。本系列中还有几篇博客文章。技术报告,线性时间RE2正则式发动机。
简·戈伊瓦尔茨(Jan Goyvaerts)有一个很好的指南,可以避免再做,尽管有一些缺点。
Jeffrey Friedl的“掌握正则表达式”包括关于慢速正则表达式引擎、redo和一些正则表达式优化的讨论。
您用编程语言编写的正则表达式由该编程语言的正则表达式引擎计算。这些引擎接受正则表达式和字符串,并决定正则表达式是否与字符串匹配。不幸的是,他们遵循的搜索算法容易浪费时间反复尝试相同的东西。
这就是正则表达式引擎的搜索过程的工作方式。正则表达式引擎查看其在正则表达式中的当前位置和字符串的当前字符,并且:
作为示例,让我们将此方法应用于字符串ab上的图片。
正则表达式引擎从左侧启动,并在路径中找到一个分叉。它看到它可以通过向上或向下匹配a-它现在将尝试一个分支,并将另一个保存到稍后。
现在它看到可以通过向上或向下匹配b-它将尝试一个分支并保存另一个分支。
现在它正在寻找一个c,但它的字符不正确。所以它会走回头路。
它尝试另一个分支来查找b,并且(冗余地)再次查找c。这将会失败,因此它将回到它最后一条没有尝试过的道路上,即a的“向下”版本。
再一次,我们到达了一对b(我们以前来过这里!),我们再一次尝试向上和向下(我们以前已经尝试过了!),到达c,但失败了。
正则表达式引擎最终通过四条不同的路径查找c四次,这四条路径都指向相同的点。
让我们再举一个例子。这个问题比前一个更难理解,但它也更能代表现实软件中出现的正则表达式问题(请参阅堆栈溢出中断)。那么让我们在这张图片上尝试这种方法,字符串为aaa…。长度为N+1个字母的AAB。
正则表达式引擎从左侧启动,并且有一个选择:它可以使用循环中的第一个a(然后再次面临相同的选择),或者跳过循环转到下一个循环。
一旦它进入第二个循环,它就会消耗掉那里剩下的a。
一旦所有的A都用完了,它就会遇到B并拒绝该搜索路径。
通过一些推理,我们可以计算出正则表达式引擎将尝试多少不同的失败路径。逻辑是这样的:
正则表达式引擎有一系列a要使用。它可以将该序列分成“左半部分”和“右半部分”,并将左半部分馈送到第一个A-环,将右半个馈送到第二个A-环。
每个循环可以在没有a和所有a之间消耗,所以我们可以在N个点划分字符串-这些是第一个a-循环中的N个决策点,我们在这里决定是停留还是前进。
因此,我们有N条失败路径,每条路径都要求我们消耗字符串中的所有N个字符。这意味着算法在宣布故障之前总共需要N²个步骤。这是一个轻微的简化,因为路径共享一些工作-N条路径分别产生1个不同的步骤、2个不同的步骤,依此类推,成本为1+2+…。+N-1+N=N²。
同样,我们在搜索中有一堆冗余-这些路径最终都会在第二个a循环中结束。
对于一根短的弦来说,N²不算太差。但是由于正则表达式在整个系统堆栈中都被使用,有时是在非常长的字符串上,所以这也可能是一个问题。