为什么Skylake CPU有时会慢50%-英特尔是如何破坏现有代码的
我接到电话说,在较新的硬件上,一些性能回归测试变慢了。没什么大不了的。通常是Windows中某处的配置不正确,或者某些BIOS设置设置为非最佳值。但这一次,我们找不到一个确实能让性能恢复正常的设置。由于9s与19s的变化不小(蓝色是旧硬件,橙色是新硬件),我们需要更深入地研究:
性能从9,1秒下降到19,6秒绝对是非常显著的。我们做了更多的检查,看测试中的软件版本、Windows、BIOS设置是否与旧的基准硬件有所不同。但不是所有的东西都是一样的。唯一的区别是相同的测试在不同的CPU上运行。下面是最新CPU的图片。
Xeon Gold运行在名为Skylake的不同CPU架构上,这是英特尔自2017年年中以来生产的所有CPU通用的架构。*正如评论者指出的那样,消费级Skylake CPU已经于2015年发布。带有SkylakeX的服务器至强CPU于2017年年中发布。所有以后的CPU,卡比湖,…。都有相同的问题。如果您购买的是当前的硬件,您将获得一个采用Skylake CPU架构的CPU。这些都是不错的机器,但正如测试表明的那样,更新和较慢并不是正确的方向。如果所有这些都失败了,那么就得到一个复制品,并使用真正的分析器™来深入挖掘。当您在旧硬件和新硬件上记录相同的测试时,应该会很快到达某个位置:
请记住,WPA*中的diff视图(Windows Performance Analyzer是免费的评测UI,是Windows SDK的一部分Windows Performance Toolkit的一部分)在表中显示跟踪2(11s)-跟踪1(19s)的增量。因此,表中的负增量表示较慢测试的CPU消耗增加。当我们查看最大的cpu消费者差异时,我们会发现AwareLock::Configuration、JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel和ThreadNative.SpinWait。当线程竞争锁时,一切都指向CPU旋转。但这是假的转移注意力,因为旋转并不是性能降低的根本原因。增加的锁争用意味着我们软件中的某些东西在持有锁时确实变慢了,因此导致更多的CPU旋转。我正在检查锁定时间和其他关键指标,如磁盘等,但我找不到任何相关的东西来解释性能下降的原因。虽然不符合逻辑,但我还是用各种方法重新讨论了增加的CPU消耗。
找出CPU到底卡在哪里会很有趣。WPA有文件列和行列,但是这些列只适用于私有符号,我们没有这些符号,因为它是.NET Framework代码。其次最好的方法是获取指令所在的DLL地址,该地址称为映像RVA(相对虚拟地址)。当我将相同的DLL加载到调试器中,然后执行。
然后我应该看到消耗CPU周期最多的指令,它基本上只有一个热地址。
0:000>;u clr.dll+0x195 66B-10clr!AwareLock::Contention+0x135:00007ff8`0535565b f00f4cc6 lock cmovl eax,esi00007ff8`0535565f 2bf0 subesi,eax00007ff8`05355661 eb01 JMP clr!AwareLock::争用+0x13f(00007ff8`05355664)00007ff8`05355663 cc int 300007ff。
0:000>;u clr.dll+0x 2801-10clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:00007ff8`051c27f1 5E POP rsi00007ff8`051c27f2 c3 ret00007ff8`051c27f3 833d0679930001 CMP双字ptr[clr!g_系统信息+0x20(00007ff8`05afa100)],100007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a(00007ff8`05afa100)
现在我们有了一个模式。热位置一次是跳转指令,另一次是减法。但是这两个热指令之前都有相同的名为PAUSE的公共指令。由于某些原因,不同的方法执行相同的CPU指令非常耗时。让我们测量一下暂停指令的持续时间,看看我们是否在正确的轨道上。
暂停在新的Skylake CPU上的速度要慢一个数量级。当然,事情可以变得更快,有时也会慢一点。但是速度要慢10倍以上呢?听起来更像是窃听器。在互联网上搜索一下暂停指令就可以找到英特尔手册,其中明确提到了Skylake微体系结构和暂停指令:
不,这不是错误,这是一个有文档记录的功能。甚至还存在一个网页,其中包含几乎所有CPU指令的计时。
这些数字是CPU周期。要计算实际时间,需要将周期数除以CPU频率(通常为GHz),以得到以ns为单位的时间。
这意味着当我在最新硬件上的.NET上执行大量多线程应用程序时,速度会变得慢得多。其他人已经在2017年8月注意到了这一点,并为其写了一期:https://github.com/dotnet/coreclr/issues/13388.。该问题已在.NET Core 2.1中修复,.NET Framework 4.8预览也包含该问题的修复。
改进了几个同步原语中的自旋等待,以便在英特尔Skylake和更新的微体系结构上更好地执行。[495945,mscallib.dll,错误]。
但是,因为.NET4.8还需要一年时间,所以我已经申请了一个补丁的后端口,以使.NET4.7.2在最新的硬件上恢复速度。由于.NET的许多部分都在使用旋转锁,因此您应该注意Thread.SpinWait和其他旋转方法会增加CPU消耗。
例如,Task.Result将在内部旋转,我可以在其他测试中看到CPU消耗的显著增加和性能的降低。
在调用WaitForSingleObject来支付“昂贵的”上下文切换之前,我已经查看了.NET核心代码,当锁没有释放时,CPU将保持旋转多长时间。上下文切换位于微秒范围内,当多个线程都在等待同一内核对象时,上下文切换会变得慢得多。
.NET Lock将最大旋转持续时间乘以内核数量,这考虑到了完全竞争的情况,即每个内核都有一个线程等待相同的锁,并尝试旋转足够长的时间,以便每个人在支付内核调用费用之前都有机会工作一段时间。在.NET中旋转使用指数回退算法,其中旋转从循环中的50个暂停调用开始,对于每次迭代,旋转数量乘以3,直到下一个旋转计数大于最大旋转持续时间。我已经计算了线程在不同核心数的Pre Skylake CPU和当前Skylake CPU上旋转的总时间:
/<;Summary>;/这是.NET在锁争用减去锁获取期间的旋转方式/SwitchToThread/休眠调用/<;/Summary>;/<;param name=";nCores";>;<;/param>;void Spin(Int NCores){const int dwRepltions=10;const int dwInitialDuration=0。i++){int Duration=dwInitialDuration;Do{for(int k=0;k<;Do;k++){call_pause();}Duration*=dwBackOfffactor;}While(Duration<;dwMaximumDuration);}}。
旧的旋转时间在毫秒范围内(24个内核的旋转时间为19ms),与总是提到的高成本的上下文切换相比已经相当多了,后者要快一个数量级。但是对于Skylake CPU,争用锁的总CPU旋转时间呈爆炸式增长,我们将在24核或48核计算机上旋转高达246毫秒,这仅仅是因为新的英特尔CPU的延迟将暂停指令增加了14倍。情况真的是这样吗?我已经创建了一个小型测试器来检查完整的CPU旋转,计算出的数字很好地符合我的预期。我有48个线程在一台24核的机器上等待一个锁,在这里我调用Monitor。PulseAll让竞争开始:
只有一个线程会赢得比赛,但47个线程会旋转,直到放弃。这是一个实验证据,表明我们确实存在CPU消耗的问题,旋转时间过长是一个真正的问题。过度旋转会损害可伸缩性,因为CPU周期会消耗在其他线程可能需要CPU的地方,尽管使用PAUSE指令会在“休眠”时间更长的情况下释放一些共享的CPU资源。旋转的原因是为了在不进入内核的情况下快速获取锁。如果这是真的,增加的CPU消耗在任务管理器中可能看起来不太好,但只要还有内核可供其他任务使用,就不会影响性能。但是测试表明,几乎单线程操作(其中一个线程向工作队列添加一些内容,而工作线程等待工作,然后对工作项执行某些任务)会变慢。
这其中的原因可以用图表来最好地说明。争用锁的旋转是在每个步骤之后旋转三倍的步骤中进行的。在每次旋转之后,锁再次检查当前线程是否可以获得它。在旋转时,锁试图保持公平,并不时切换到其他线程,以帮助其他线程完成其工作。这增加了我们稍后再次检查时锁被释放的可能性。问题是,只有在一个完整的旋转回合完成锁定之后,才能检查是否可以进行以下操作:
例如,如果在旋转第五轮期间,锁定在我们开始第五轮之后立即发出信号,我们将等待完整的旋转循环,直到我们可以获得锁定。通过计算最后一轮的旋转持续时间,我们可以估计线程可能出现的最坏延迟情况:
这是我们可以等待很多毫秒,直到旋转完成。这真的是个问题吗?
我已经创建了一个简单的测试应用程序,它实现了生产者消费者队列,其中工作线程为每个工作项工作10ms,消费者在发送下一个工作项之前有1-9ms的延迟。这足以看到效果:
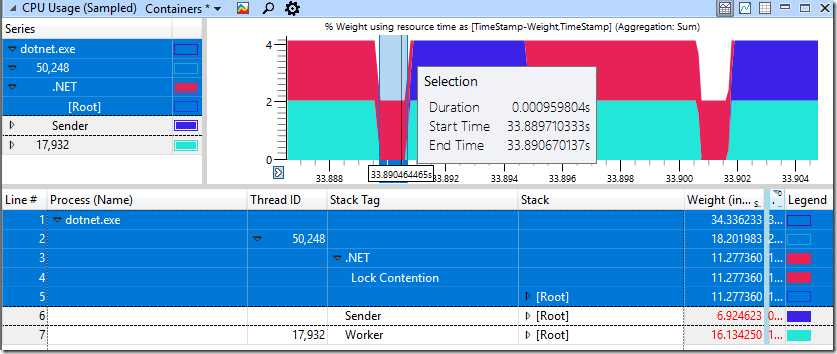
我们看到,对于一些发送者线程延迟为1毫秒和2毫秒,总持续时间为2,2s,而对于其他时间,我们的速度是大约1,2s的两倍。这表明过度的CPU旋转不仅是一个表面上的问题,它只会严重损害多线程应用程序,而且还会影响只涉及两个线程的简单生产者-消费者线程。对于上面的运行,ETW数据本身就说明CPU旋转增加确实是观察到的延迟的原因:
当我们放大到慢速部分时,我们发现红色的旋转时间为11毫秒,尽管工人(浅蓝色)已经完成了工作,并且很久以前就已经归还了锁。
快速非退化的情况看起来要好得多,其中只有1ms用于锁的旋转。
我使用的测试应用程序名为SkylakeXPause,位于https://1drv.ms/u/s!AhcFq7XO98yJgsMDiyTk6ZEt9pDXGA,其中包含一个压缩文件,其中包含.NET Core和.NET4.5的源代码和二进制文件。我实际做的比较是在Skylake机器上安装了.NET4.8Preview,它包含了补丁,以及.NETCore2.0,它仍然实现了旧的旋转行为。该应用程序的目标是.NET Standard 2.0和.NET4.5,它们会生成一个exe和一个DLL。现在我可以并排测试新旧的旋转行为,而不需要修补任何东西,这非常方便。
readonly object_LockObject=new object();int WorkItems;int CompletedWorkItems;Barrier SyncPoint;void RunSlowTest(){const int processingTimeinms=10;const int WorkItemsToSend=100;Console.WriteLine($";Worker线程工作{processingTimeinms}ms,{WorkItemsToSend}次";);//测试一个发送方和一个接收方线程。确保Worker首先启动Double[]sendDelayTimes={1,2,3,4,5,6,7,8,9};foreach(Var SendDelay In SendDelayTimes){SyncPoint=new Barrier(2);//一个发送者一个接收者var sw=Stopwatch.StartNew();Parallel.Invoke(()=>;Sender(workItems:WorkItemsToSend,delayInms:Console.WriteLine($";发送延迟:{sendDelay:f1}毫秒工作在{sw.Elapsed.TotalSeconds:F3}s";);Thread.Sept(100);//显示ETW数据中的一些差距,以便我们可以区分测试运行}}/<;Summary>;/模拟消耗由发送方线程触发的CPU的工作线程/<;/Summary>;void worker(int maxWorkItemsToWorker。While(CompletedWorkItems!=maxWorkItemsToWork){lock(_LockObject){if(WorkItems==0){Monitor or.Wait(_LockObject);//等待工作}for(int i=0;i<;WorkItems;i++){CompletedWorkItems++;SimulateWork(WorkItemProcessTimeInms);//消耗此锁下的CPU}WorkItm/在锁下插入工作线程的工作,唤醒工作线程n次/<;/Summary>;void Sender(int workItems,Double delayInms){CompletedWorkItems=0;//删除前一工作SyncPoint.SignalAndWait();for(int i=0;i<;workItems;i++){lock(_LockObject){WorkItems++;Monitor or.PulseAll(_LockObject);}SimulateWork(DelayInms);}}。
这不是.NET问题。它会影响所有使用暂停指令的自旋锁定实现。我已经对Server2016的Windows内核进行了快速检查,但没有发现类似的问题。看起来英特尔很友好地给了他们一个暗示,需要在旋转策略上做出一些改变。
当该问题于2017年8月报告给.NET Core时,即2017年9月,该问题已通过.NET Core 2.0.3(https://github.com/dotnet/coreclr/issues/13388).)修复并推出。这不仅是因为.NET核心团队的反应速度令人惊叹,而且这个问题在几天前也已经在Mono分支上得到了解决,关于更多旋转改进的讨论正在进行中。不幸的是,桌面.NET Framework的发展速度没有那么快,但至少我们在.NET Framework4.8预览版中至少有一个概念证明,修复程序在那里也可以工作。现在我正在等待.NET4.7.2的后端口,以便能够在最新的硬件上全速使用.NET。这是我的第一个bug,它与一条CPU指令中的性能变化直接相关。ETW仍然是Windows上的首选评测工具。如果我有一个愿望,我会让微软把ETW基础设施移植到Linux上,因为当前的性能工具在Linux上仍然很糟糕。有一些我
如果您在2017年年中以后生产的CPU上运行.NET Core 2.0或桌面.NET Framework,如果您因此问题而运行速度较慢,则绝对应该使用分析器检查您的应用程序,并升级到更新的.NET Core,希望很快就能升级到.NET Desktop版本。我的测试应用程序可以告诉您您是否可能遇到问题。
D:\SkylakeXPause\bin\Release\netcoreapp2.0>;dotnet SkylakeXPause.dll-checkDid调用在3.5990毫秒内暂停1,000,000,处理器:8未检测到SkylakeX问题或D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>;SkylakeXPause.exe-checkDid调用在3.6195毫秒内暂停1,000,000,处理器:8未检测到SkylakeX问题。
仅当您在Skylake CPU上运行未修复的.NET Framework时,该工具才会报告问题。我希望你确实和我一样觉得这个问题很吸引人。要真正理解一个问题,您需要创建一个复制器,该复制器允许您进行实验,以找到所有相关的影响因素。剩下的都是枯燥乏味的工作,但是现在我更好地理解了CPU旋转的原因和后果。
*表示更改,以使事情更清晰,并增加新的见解。这篇文章在黑客新闻(https://news.ycombinator.com/item?id=17336853)和Reddit)(https://www.reddit.com/r/programming/comments/8ry9u6/why_skylake_cpus_are_sometimes_50_slower/).)上获得了相当大的吸引力。它甚至在维基百科(https://en.wikipedia.org/wiki/Skylake_(microarchitecture)).)中被提及。哇。谢谢你的关心。