语义图像合成与单幅图像生成模型的学习
计算机视觉中的GANS:语义图像合成和从单个图像学习生成模型(第6部分)。
到目前为止,我们已经看到了多个计算机视觉任务,如对象生成、视频合成、未配对的图像到图像的转换。现在,我们已经达到了2019年的出版物,在我们的旅程中,我们总结了从甘斯开始的所有最有影响力的作品。我们关注的是直觉和设计选择,而不是无聊的数字报告。最后,如果结果不吸引人,那么在视觉生成任务中报告的数字的价值是什么?
在这一部分,我们选择了两种独特的出版物:基于分割图的图像合成和基于单个参考图像的无条件生成。我们提出了在设计GaN时必须考虑的多个角度。我们将在本教程中访问的模型已经从多个角度解决了开箱即用的任务。
我们已经看到了很多将分割图作为输入并输出图像的作品。当一些事情是好的时候,我脑海中总是浮现的问题是:我们能做得更好吗?
比方说,我们可以在这个想法上做更多的扩展。假设我们想要在给定分割图和参考图像的情况下生成图像。这项任务被定义为语义图像合成,具有非常重要的意义。我们不仅根据分割图生成不同的图像,而且还进一步约束我们的模型以考虑到我们想要的参考图像。
这项工作是NVIDIA在Gans中的计算机视觉的缩影。它很大程度上借鉴了之前的Pix2PixHD和StyleGan的作品。实际上,他们借用了Pix2PixHD的多尺度鉴别器。让我们来看看它是如何工作的:
在此基础上,他们还对StyleGan的发电机进行了检查。该模型的生成器使用自适应实例归一化(ADAIN)对潜在空间表示的风格进行编码。基本上,它接收噪声,这就是建模风格。有趣的是,他们发现adain会丢弃语义内容。让我们来看看为什么:
[adain(x,y)=\sigma(Y)(\frac{x-\m u(X)}{\sigma(X)})+\m u(Y)\]在这个方程中,我们使用特征映射的统计量来归一化它的值。这意味着格网结构中的所有要素都按相同的量进行了规格化。由于我们要设计一个用于样式和语义解缠的生成器,因此对语义进行编码的一种方法是对层内归一化进行调制。让我们看看如何通过空间自适应反规格化来设计它,或者干脆用铲子!
我们将从丢弃上一层统计信息开始。因此,对于由索引i表示的网络中的每一层,使用激活\(h\)和\(N\)样本,我们将像往常一样归一化通道维度。与批量归一化类似,我们将首先使用通道的平均值和标准差进行归一化。
\[\µ_{c}^{i}=\frac{1}{N H^{i}W^{i}}\sum_{n,y,x}h_{n,c,y,x}^{i}\]\[\sigma_{c}^{i}=\sqrt{\frac{1}{N H^{i}W^{i}}\sum_{n,y,x}(h_{n,c,y,x}^{i})^2-(\mu{c}^{i})^2)}\]\[val_{c}^{i}=\frac{h_{n,c,y,x}^{i}-\mu{c}^{i}}{\sigma{c}^{i}}\]\[\γ_{c,y,x}^i*val_{c}^{i}+\beta_{c,y,这类似于批处理规范的第一步。最后一个公式中的val是规格化值,它对于2D栅格中的所有值都是相同的。
但是,因为我们不想丢失网格结构,所以我们不会相等地重新调整所有值的比例。与现有的规格化方法不同,新的缩放值将是3D张量(而不是向量!)。确切地说,给定具有两个输出(在文献中通常称为头部)的两层卷积网络,我们有:
\[\boldSymbol{\Gamma}=Conv_{1}(Conv(MASK_{SEGM}))\]\[\boldSymbol{\beta}=Conv_{2}(Conv(MASK_{SEGM}))\]\]\[两者\四\boldSymbol{\Gamma},\boldSymbol{\beta}\在R^{C,H,W}\]由于分段映射不包含连续值,我们通过2卷积将其投影到嵌入空间中。
基本上,2D栅格(y,x)中的每个位置都有自己的比例参数,根据输入分段图,每个位置都不同。因此,学习到的新缩放(调制)参数自然编码由分段图提供的关于标签布局的信息。在原著的基础上,给出了一幅令人惊叹的插图:
那么,让我们用这个空间自适应模块来构建一个积木吧!由于从第一步中丢弃了先前的统计数据,因此我们可以包括编码所需布局的不同部分的多个这样的层。请注意,不需要在生成器的输入中包括分段图!
遵循RESNET块的附加跳跃连接的体系结构,网络可以更快地收敛,并且通常在更好的局部最小值。它由归一化层位置上的两个黑桃层组成。请注意,层内归一化始终在激活函数之前应用。这样做是为了首先在零附近缩放卷积层的范围,然后修剪值。
由于分段图信息被编码在铲子构建块中,因此生成器不需要具有编码器部分。这大大减少了可训练参数的数量。
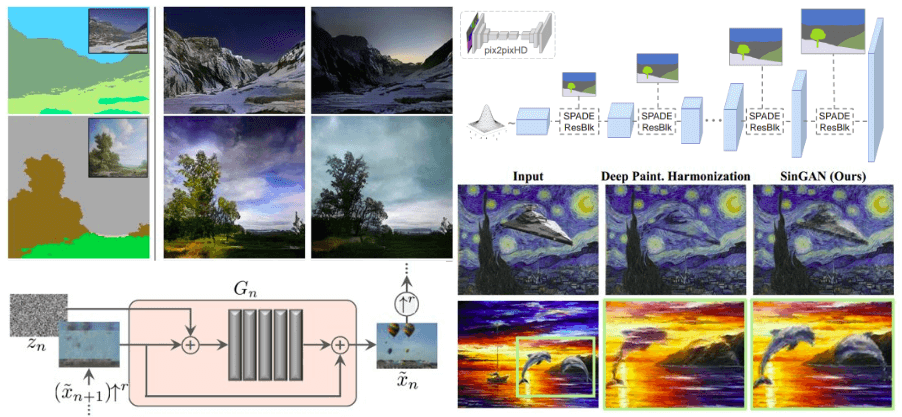
为了匹配在不同空间维度中操作的生成器的每一层,对分段图进行下采样。Spade RES-net块与上采样层相结合。综上所述,基于黑桃的生成器中的分割掩码是通过空间自适应调制馈送的,而不需要额外的归一化。只有来自先前卷积层的激活被规格化。这种方法在不丢失语义信息的情况下以某种方式结合了标准化的优点。他们引入了空间变化的层内归一化的概念,这是该领域一项新颖而重要的长期贡献。为了记录起见,分割图是使用Chen等人2017年训练过的DeepLab版本2模型来推断的。以上所有情况可以说明如下:
该生成器将语义分割注入到SPADE RES块中。这张照片是照原作拍的。
同时,由于生成器可以接受随机向量作为输入,因此它实现了基于参考图像的图像合成的自然方式。这通常被称为多模态图像合成。简单地说,我们将潜在空间建模为参考图像的表示。更具体地说,可以添加将真实图像嵌入随机向量的图像编码器。然后将其送入发电机。编码器与生成器耦合形成抽象的变分自动编码器VAE(Kigma等人,2013)。以不同的方式编码两个输入,即真实图像和分割图。编码器尝试捕捉图像的风格,而G通过黑桃组合编码的风格和分割掩码信息以生成新的视觉吸引力的图像。
在我的拙见中,除了铁锹生成器之外,作者将基准的Pix2PixHD与该领域的所有其他进步一起应用,这一点非常重要,因为它们工作得更好。因此,他们引入了名为Pix2PixHD++的基线。这是非常重要的,因为它可以立即显示建议的层的有效性。有趣的是,基于铁锹的解码器G在参数数量较少的情况下比扩展基线的Pix2PixHD++工作得更好。
此外,他们还包括一项巨大的消融研究,以加强该方法的有效性。黑桃生成器是第一个语义图像合成模型。它为包括室内、室外和风景场景在内的多个场景产生不同的照片级真实感输出。还有一个你可以亲眼看到的在线演示。相信我,这值得一试。下面是与分割图的真实图像的比较。尽管听起来很疯狂,但这些照片是由高干制作的!
与原始自然图像进行对比。语义图像合成在行动中,借用原著。
最后,现在你了解了高干背后的魔力,你就可以享受官方视频了。您也可以访问官方项目页面了解更多结果。
到目前为止,我们讨论的每一篇论文在某些方面都有其独到之处。在著名的ICCV 2019计算机视觉大会上,这篇论文被评为最佳论文。我们看到,以前的工作是在包含数千或数百万张图像的海量数据集中进行训练的。与我们通常的直觉相反,作者表明,单个自然图像中斑块的内部统计数据可能携带了足够的信息来训练GaN。
为此,他们将单个图像作为金字塔来处理,获取一组下采样图像,并从粗略到精细探索每个尺度。为了处理不同的输入图像,他们设计了一组完全卷积的GAN。每个特定的网络都旨在捕获不同规模的分布。
这是因为核大小为K×K的二维卷积层只需要大于K的输入大小。该技术还用于用较小的输入块训练更快的模型,然后在测试时处理更大的分辨率。如果您的体系结构中有完全连接的层,这是不可能的,因为您需要预定义输入大小。
此外,他们还使用了基于补丁的鉴别器来区分像素2pix。理想情况下,提出的基于补丁的鉴别器层次结构,而每个级别捕获不同尺度的统计信息。类似于渐进式生长GAN的生成器,它们首先从小标尺开始训练,不同的是,当一个标尺被训练时,它们冻结了权重。此外,他们还使用了梯度惩罚Wasserstein GAN,以稳定训练过程。
图像样本的生成从最粗的比例开始,并顺序地通过所有生成器直到最细的比例。单个比例的典型工作流程如下所示:5conv。块之后进行批归一化,并对上采样图像进行REU激活处理。在将幻觉图像馈送到网络之前,会添加噪声。空间维度在整个块中保持不变,填充为1,内核为3。因此,可以添加一个简短的加性跳跃连接,将上采样的图像融合到块的输出。这个概念极大地帮助模型更快地收敛,正如我们在许多方法中已经看到的那样。以上所有情况可以说明如下:
SINGAN的一个比例尺的生成器的构建块。图像取自原作。
重要的是,在其他成功的作品(BigGan,StyleGan)之后,在每个尺度上都注入了噪音。原因是我们不想让发电机记住以前的刻度,因为它的训练已经停止。在同一个方向上,不同的GAN接受范围小,学习能力有限。直观地说,我们不想让补丁记住输入,因为我们只用一张图像进行训练。容量有限是指参数数量较少。
作为参考,起始层的有效接受场大约是图像高度的50%。因此,它可以生成图像的总体布局(全局结构)。上述块的接收视野为11x11,因此输入图像通常以25像素的比例开始。
有趣的是,他们选择以这样的方式设计模型:当您为最后一层(Z_FIXED)选择零作为输入噪声和固定噪声时,应该训练网络以重建原始图像。
\[l_{rec}=||G_{n}(Noise=0,x_{upsampl}^{rec})-x_{n}^{real}||^2\]\[L_{rec}=||G_{last}(Noise=z_{Fixed},x_{upsampl}^{rec})-\textbf{i}^{real}||^2\]。因此,重建图像\(x_rec\)确定每个尺度的噪声的标准偏差。
检查模型的输出,我们观察到生成的图像是逼真的,同时它们保留了原始图像的内容。由于该模型在每个面片中具有有限的感受场(小于整个图像),因此可以生成输入图像中不存在的面片的新组合。下面您可以看到模型是如何遇到外部注入模型的结构的。我们注意到,SinGan保留粘贴对象的结构,同时调整其外观和纹理。
基于本工作的大量结果,很容易推断SinGAN模型可以生成逼真的随机图像样本。令人惊讶的是,即使有了新的结构和物体调制。尽管如此,它仍会学习保留图像/补丁分布。
为了记录起见,作者还探索了用于其他图像处理任务的SinGAN。在给定训练模型的情况下,他们的想法是利用SinGAN学习训练图像的斑块分布这一事实。因此,可以通过将图像注入生成金字塔来实现操作。直观地说,该模型将尝试将其补丁分布与训练图像的补丁分布相匹配。应用包括图像超分辨率,绘画到图像,协调,图像编辑,甚至动画从一个单一的图像行走的潜在空间!
官方视频总结了我们在本教程中描述的这项工作的前述贡献。
我们仔细检查了从分割图合成图像方面表现最好的方法,以及从单个图像学习的方法。对于饥肠辘辘的读者,我们总是喜欢留下一个深思熟虑的、强烈推荐的链接。因此,既然您已经了解了很多关于设计和培训GAN的知识,我们建议您探索该领域中尚未解决的问题,Odena等人在本文中对这些问题进行了完美的描述。2019年。您总是可以在这里找到更多可能与您的问题更接近的论文。最后,您不需要自己实现每个体系结构。在Kera和Pytorch中有一个非常棒的gan git存储库,它包含多个实现。请随时查看它们。
这是本系列目前的最后一篇文章。但请注意,计算机视觉中的甘斯系列将继续开放,以包括未来的新论文,以及我们可能错过的现有论文。我们目前正在准备一本免费的电子书,它总结了我们的结论,并将我们所有的文章连接成一个单一的资源。如果您想表达您的兴趣,请订阅我们的时事通讯,直接将其接收到您的收件箱中。
@文章{adaloglo2020gans,title=";Gans in computer Vision";,作者:Adaloglou,Nikolas and Karagianakos,Sergios";,Journal=";https://theaisummer.com/";,Year=";2020";,url=";https://theaisummer.com/gan-computer-vision-semantic-synthesis/";}
朴涛、刘明义、王同昌、朱军云(2019)。空间自适应归一化的语义图像合成。载于IEEE计算机视觉和模式识别会议论文集(第2337-2346页)。
沙汉姆,T.R.,Dekel,T.,&;Michaeli,T.(2019年)。辛根:从单一的自然图像中学习生成模型。载于IEEE国际计算机视觉会议论文集(第4570-4580页)。
何凯、张霞、任山、孙军杰(2016)。深度残差学习在图像识别中的应用。发表于IEEE计算机视觉和模式识别会议论文集(第770-778页)。
陈L.C.,Papandreou,G.,Kokkinos,I.,Murphy,K.,&;Yuille,A.L.(2017)。Deeplab:基于深度卷积网络、Atrus卷积和完全连通CRF的语义图像分割。“IEEE模式分析与机器智能学报”,40(4),834-848。