渲染和编辑器之间的边界-第2部分:拾取
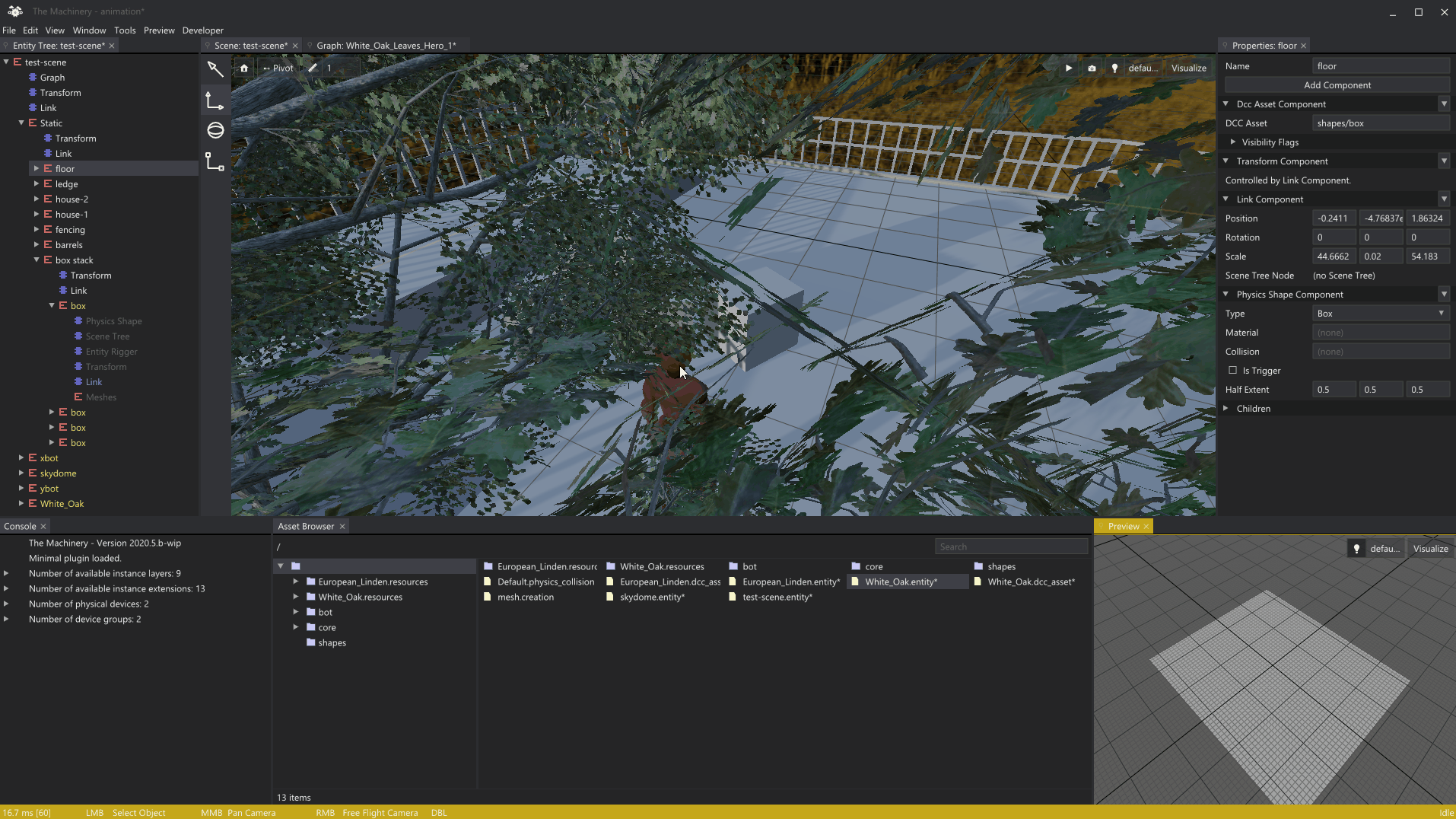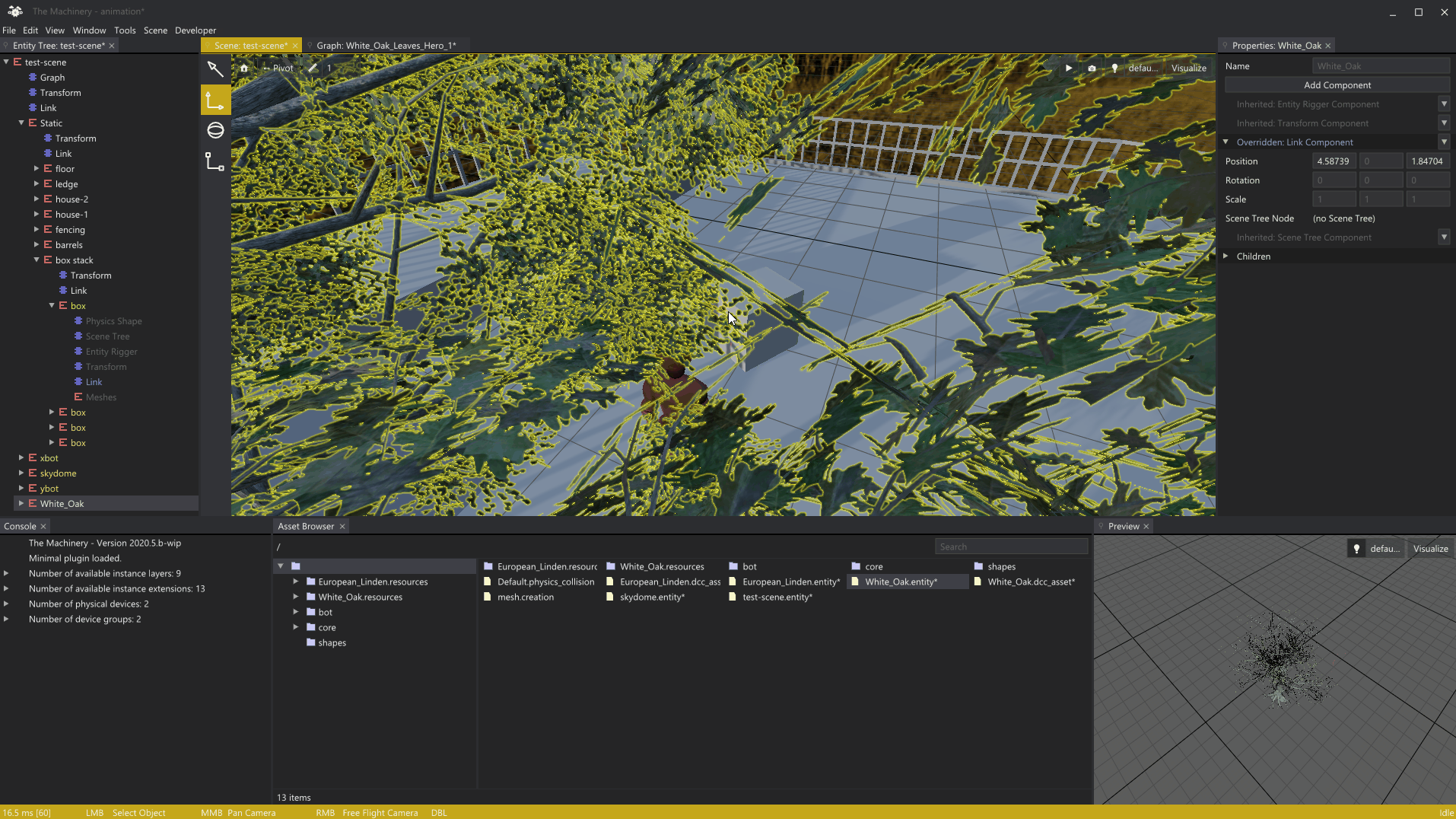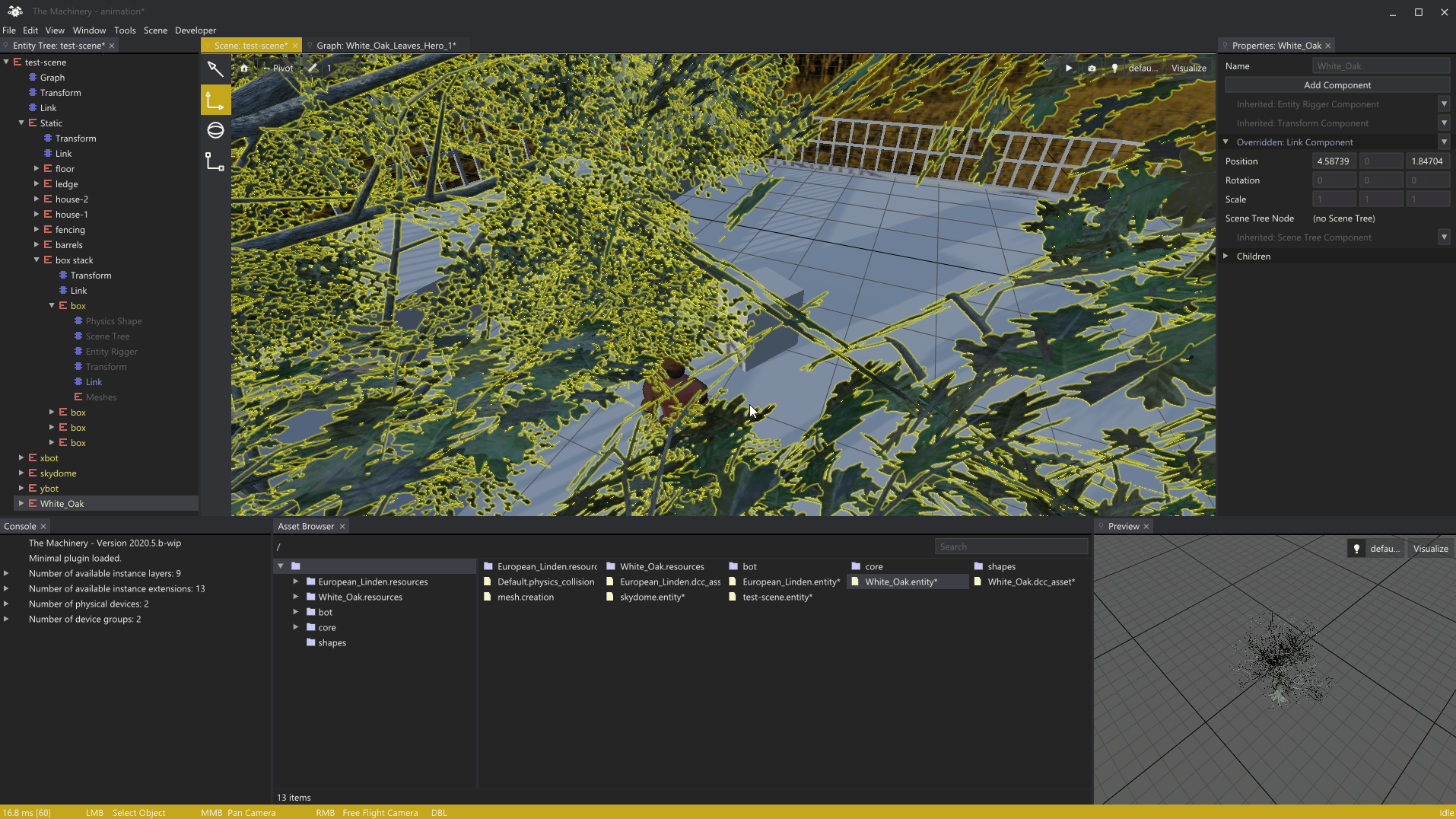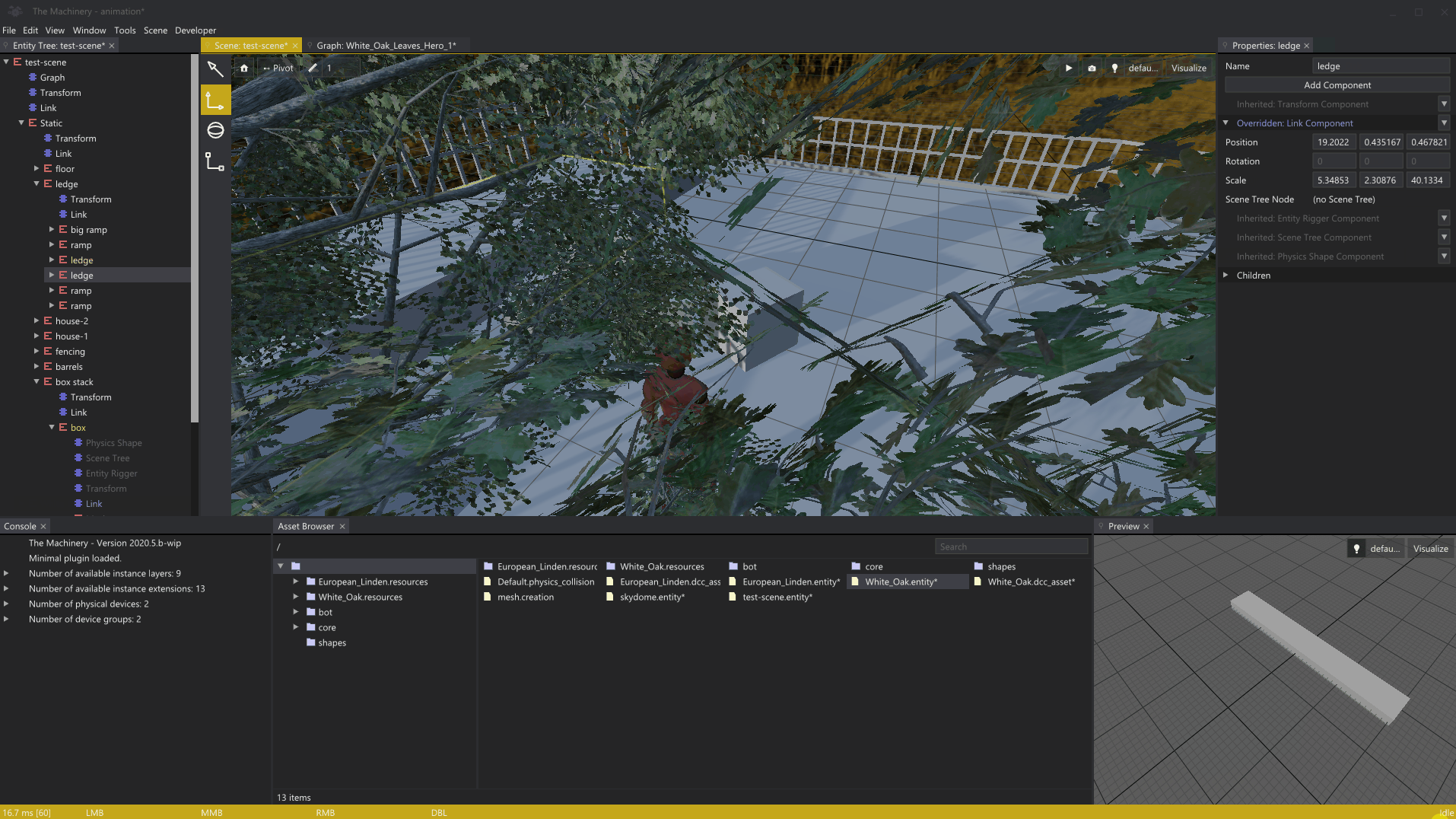
3月初,我在我们的编辑中写了一篇关于网格渲染的文章。在我们进入今天的主题之前,我想展示一下我自上一篇文章以来添加的网格渲染的一个小功能,即在启用捕捉的情况下渲染对象局部网格,以指导对象的移动:
我认为结果相当不错,感觉像是一个很好的例子,说明了Mechanical的模块化在实践中是如何工作的-只需查询对tm_grid_renender_api的访问,并添加您的插件可能需要的任何网格渲染。
不管怎样,我们继续吧。在今天的帖子中,我们将讨论如何挑选老鼠。
当用户在视口内单击时,所有类型的3D编辑器都需要某种方法来确定鼠标指针下碰巧出现的任何对象的对象标识。我会把这个过程称为“挑选”。
拾取,就像网格渲染一样,通常被认为是图形程序员关心的或者不重要的问题之一。相反,有些工具程序员往往会以这样或那样的方式提出解决方案。通常,通过鼠标指针将某种形式的光线从视口摄影机的位置投射到摄影机的近平面上。
整个情况,渲染和工具人员之间截然不同的竖井,渲染程序员的首要态度,以及两个最常见的问题解决方案,在很多方面都很糟糕,让我想哭。
例如,当您需要拾取不具有形而上学表示的对象时,物理系统就会崩溃,并且通常在视口中渲染的许多对象不需要形而上学表示。一种常见的用户解决方法是开始添加物理表示,仅仅是为了使编辑器中的内容可拾取。不理想的…。
另一方面,实现仅用于编辑拾取的特定光线投射系统可能需要大量的工作。当然,该实现不一定是世界上最快的,因为您通常每帧(或更少)只投射一条光线,但是,您肯定需要某种加速结构(如BVH-tree),因为您肯定希望拾取实际渲染的三角形,而不是某个代理。这种结构既会消耗内存,又要花一些时间来烹饪,一旦您开始处理包含大量对象(>;10K)的稍微复杂的场景,您可能就需要添加另一个级别的加速结构。(<##**$$}{##**$$})
更不用说,这两种方法都不太可能处理对可变形对象(如蒙皮角色)的拾取,或对Alpha蒙版对象(例如,树上树叶之间的对象)的拾取,或处理纯粹基于体素的对象,或任何类型的“纳米”解决方案。
很明显,这不是你想要的。即使在CPU上实现一个像样的解决方案是可行的,您真正想要的是一个基于GPU的拣选解决方案。您想知道鼠标光标下的像素的身份,而不是某个看不见的代理的身份。当您使用处理所有类型的几何体变形和曲面类型的象素完美解决方案时,您将永远不会再接受任何不太精确的解决方案。
具有讽刺意味的是,实现基于GPU的拣选解决方案的基础实际上非常简单,比您能想到的任何基于CPU的拣选解决方案都容易得多。那么让我们来看看我们在“机械”中的实现。
首先,我们的解决方案依赖于几个前提条件,所以让我们把它们去掉,因为我不会在这篇文章中更详细地介绍它们:
首先,我们依赖于我们的着色器系统能够有效地为视口中所有绘制的对象选择不同的着色器变体。我们使用本文描述的“系统”概念来处理这个问题。
其次,我们始终依赖于支持将无序访问视图(UAV)绑定到像素着色器的硬件。
所以这个想法很简单。当用户在视口内单击时,我们将激活一个名为Pick_System的特殊着色器系统。这意味着实现对Pick_System支持的任何着色器将在用于在屏幕上渲染对象的像素(或计算)着色器中激活略有不同的代码路径。
激活的着色器变体添加了对在PICKING_SYSTEM中定义的UPDATE_PICKING_BUFFER()的调用。实际的拾取缓冲区与一个12字节的缓冲区一样愚蠢,绑定为auav,包装了一个简单的结构:
//`pos`应为SV_Position.xy(或CS类似的文字)。/`Identity`为渲染对象的唯一标识。在TM中,这通常是发布GPU工作的实体的ID。/`z`是着色点的Z深度值。/`opacity`是当前着色像素的不透明度值。void update_Pick_Buffers(uint2位置,uint2身份,浮动z,浮动不透明度){//如果像素的不透明度小于";不透明度拾取阈值";//--返回。if(opacity<;load_opacity_Threshold())返回;//如果该像素不在鼠标光标下--返回。uint2 CURSOR_POS=LOAD_CURSOR_POS();IF(pos.x!=Cursor_pos.x||pos.y!=Cursor_pos.y)return;//将像素z与//PICKING_BUFFER中当前存储的z值进行比较。如果它大于或等于(后面)--返回。uint d=asuint(Z);if(d>;=Pick_Buffer.Load(0))return;//更新拣货缓冲区。PICKING_Buffer.Store3(0,uint3(d,身份));}。
虽然这种幼稚的实现在大多数情况下会产生正确的拾取结果,但它有时会失败,并返回最近曲面后面的拾取结果。这是因为我们需要防止并发访问PICKING_BUFFER。
我们可以结合使用原子和利用d的符号位来实现自旋锁定机制,以防止对PICKING_BUFFER进行并发更新。该实现是一个bithair,但看起来如下所示:
uint d=asuint(Z);uint current_d_or_lock=0;do{//`z`在存储的z值后面,立即返回。if(d>;=PickingBuffer.Load(0))返回;//执行原子min。`current_d_or_locked`保存当前存储的//值。PICKING_Buffer.InterlockedMin(0,d,CURRENT_d_OR_LOCKED);//我们依靠符号位来指示拣选缓冲区是否//当前被锁定。这意味着只有当//缓冲区解锁并且`d`小于当前存储的`d`时,才会进入此分支。if(d<;(Int)current_d_or_lock){uint last_d=0;//尝试通过设置符号位获取写锁定。PICKING_Buffer.InterlockedCompareExchange(0,d,asuint(-(Int)d),last_d);//只有写锁成功才会执行此分支。if(last_d==d){//更新对象标识。PICKING_Buffer.Store2(4,Identity);uint虚拟;//释放写锁。Pick_Buffer.InterlockedExchange(0,d,ummy);}}//旋转直到释放写锁定。}While((Int)Current_d_or_Locked<;0);
自旋锁定更新到位后,您应该始终在拾取缓冲区中获得最近的曲面。
这就是着色器方面的内容,现在让我们转到CPU端,看看我们为调度和将PICKING_BUFFER的结果从GPU读回CPU而准备的C-API。它名为tm_gpu_Pick_api,如下所示:
struct tm_GPU_PICKING_API{struct tm_GPU_PICKING_O*(*CREATE)(struct tm_allocator_i*allocator,struct tm_renender_resource_command_buffer_o*res_buf,struct tm_shader_system_o*Pick_system,struct tm_shader_o*clear_Pick_Buffer_shader);void(*DESTORY)(structm_gpu_Pick_o*。bool(*update_cpu)(struct tm_GPU_PICKING_o*inst,struct tm_renender_backend_i*rb,bool activate_system,const tm_ve2_t Cursor_position,Float Opacity_Threshold,uint64_t*result);void(*update_GPU)(struct tm_GPU_Pick_o*inst,struct tm_shader_system_context_o*context,struct tm_renent。};
Create()和Destroy()只负责创建和销毁拾取对象。每个支持拾取的视口都有自己的tm_GPU_PICKING_O。在内部,tm_GPU_PICKING_O拥有PICKING_BUFFER和一些状态。
检查是否有新的回读结果可用于PICKING_BUFFER。如果是,则在RESULT中返回PICKING_BUFFER的标识部分,并且函数返回TRUE。机械中的ObjectSelection跟踪是基于实体ID的,因此我们可以简单地将实体ID作为常量缓冲区的一部分传递给所有绘制和调度调用,这意味着可以直接使用返回的ValueIn结果,而无需任何额外的查找。
如果用户在视口内的某个地方单击了鼠标按钮,则应将true与光标位置和任意不透明度阈值一起传递给activate_system。这将准备将通过常量缓冲区传递给PICKING_SYSTEM的状态,并将其排队以供激活。不透明度阈值控制应在哪个曲面不透明度值处单击(即,拒绝)像素。我有计划在编辑器中公开对不透明阈值的控制,但还没有抽出时间,现在我们只通过了0.5,这感觉像是一个像样的默认值。任何不透明度小于0.5的像素都将被单击。
每当我们要渲染视口时,都会调用update_gpu()。它执行以下操作:
如果在最后一次调用update_cpu()时没有激活PICKING_SYSTEM,它会立即旋转。
将计算调度调用排队以清除PICKING_BUFFER,该调用计划在视口中发生任何其他渲染之前执行。
使用传递给update_cpu()的鼠标光标位置和不透明度阈值更新与PICKING_SYSTEM关联的常量缓冲区。
将PICKING_BUFFER的异步读回操作从GPU排队到CPU,计划在视口中所有渲染完成后运行。
由于我们不希望在回读PICKING_BUFFER的过程中使GPU停滞,因此它可能需要几个帧,直到结果可用并且从update_cpu()返回true。但在实践中,从用户的角度来看,这种延迟并不明显。
使用基于GPU的拾取解决方案,您再也不必在CPU端纠结复杂的拾取代码,只要着色器实现了不超过几行代码的PICKING_SYSTEM,屏幕上可视化的任何东西都可以拾取。
还要注意的是,虽然上面的代码示例只涵盖像素完美的选择,但没有什么能阻止您将其扩展为执行更多的模糊选择,只需计算光标与当前像素之间的距离并接受小于n像素的距离值。这在处理编辑器小工具和类似工具的选择时会很有用。