使用C++标准库生成随机数存在的问题
最近,我发现自己再次在论坛上写了一篇长篇帖子,内容是关于C++标准提供的随机数生成工具(C++;S<;Random>;和C';Rand)在C++中存在的问题。因为我一直在写这些,所以我决定把它们都写到一个博客帖子里,这样我以后就可以把它链接到人们身上。这就是那篇博文。
对这篇文章的简要总结是,使用C++的标准库来生成随机数不是一个好主意,你应该使用自己的库,或者使用现有的库。我推荐C++PCG实用程序,或者,如果您已经使用过Boost,可以使用Boost.Random";。
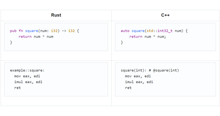
在这篇文章中,我们将使用一项应该很简单的任务:生成范围为[0,100k)的一组均匀分布的整数。
//按时间播种。不是真的随机。std::srand(std::time(Nullptr));//为(size_t_=0;_<;1';000;++_){std::cout<;<;std::Rand()%100&39;000<;<;生成1';000<;<;范围为0-100&39;000<;<;\n';
这段代码很容易编写和理解,但也有很多问题。
由此产生的数字将不会均匀分布。由于模数的使用,结果将偏向较小的数字。
代码是否线程安全取决于实现。哪些函数调用rand也取决于实现,因此数据竞争可能会在您意想不到的情况下发生。
如果您不明白为什么使用模数转换数字会导致非均匀分布的结果,请考虑一个简单的例子,其中std::Rand只能返回0、1或2,每个返回的概率都相同,并且我们需要范围[0,2]中的数字。有两种方法可以得到0,0%2和2%2,而只有一种方法可以得到1,1%2。换句话说,由于使用了模数,我们得到了0和1的2:1比率。
第二个问题比较晦涩,但更容易理解。由std::RAND生成的可能值的范围被指定为[0,RAND_MAX),其中RAND_MAX可以是大于或等于32767的任何常数。在使用此下限的平台上[1],上面的示例永远不会打印大于32767的数字。
前两个问题是可以解决的。用拒绝采样替换模数(如果需要,还可能多次调用std::rand)解决了偏差问题。要生成大于RAND_MAX的值,只需将多个调用的结果连接到std::Rand即可。
线程安全在一般情况下是不可能解决的[2],但在特定情况下,您可以使用互斥锁保护用户代码对std::Rand的调用,并且它应该工作得足够好。有些实现提供了每线程std::Rand,这是一个更好的解决方案,但是您不能依赖它。
然而,要解决所有这些问题要么是不可能的,要么是要做大量的工作,即使这样,您也会遇到这样一个问题,即允许std::rand在给定相同种子的不同平台上返回不同的数字。此时,编写您自己的随机数生成工具集变得更容易了,因此C++11以<;Random>;的形式标准化了它自己的集。
乍一看,对于一项简单的任务来说,<;Random>;似乎非常复杂。您必须选择一个模板化的均匀随机位生成器,可能会对其进行播种,选择一个模板化的分布,然后将URBG的一个实例传递给该分布以获得一个数字……。以下是使用<;Random>;重写的C示例:
//真正随机的种子。std::mt19937 rng(std::Random_Device{}());//避免一直构造分布std::uniform_int_Distribution<;>;dist(0,100';000);//为(size_t_=0;_<;1';000;++_){std::cout<;&)生成1';000个随机数(size_t_=0;_<;1';000;++_){std::cout<;&。
与C相比,这里的代码稍微多了一些,但还是可以忍受的,而且大多数问题都得到了修复。分布将是均匀的,所需间隔内的所有数字都是可能的,并且代码是线程安全的。
乍一看,<;Random>;令人敬畏,即使有一些简单操作的样板。可分解和可插拔的设计意味着您可以通过只替换随机数生成管道的一小部分来自定义您的随机数。该标准还提供了广泛的随机数引擎和分发[3],因此您应该能够做您想做的大多数开箱即用的事情。它甚至提供了一个抽象,用于获取用于播种生成器std::Random_Device的实际随机数。
乍一看,当你开始广泛使用并深入挖掘时,你会发现它的每一个部分都有很深的缺陷,最好的解决方案是避免完全使用它。
然后就不谈便携性了吗?这是因为C和C++这两个代码片段都有一个问题。即使您硬编码种子,这些代码片段也会在不同的平台上给出不同的结果[4]。对于加分,甚至不能保证结果在同一标准库的不同版本之间是可移植的,因为标准库实现被允许改变它们实现std::uniform_int_Distribution[5]的方式。
归根结底,如果您对生成的随机数有可重复性要求[6],那么您就不能使用标准提供的发行版。幸运的是,使用<;Random&>生成的随机数已被正确分解,您可以编写自己的发行版,然后继续使用<;Random>;的其余部分,对吗?
C++代码段使用std::Random_Device生成一些初始随机性,以std::mt19937的形式作为Mersenne Twister实例的种子。问题是std::Random_Device指定得很差,而且难以理解。
从理论上讲,它应该作为某种外部熵来源的抽象。在实践中,允许实现使用任何确定性随机数引擎来实现它,例如Mersenne twister,并且没有办法找到答案。有一个成员函数std::Random_Device::Effence(),理论上它可以检测这种情况,但在实践中不起作用。
这方面的责任在标准和实现之间分担。函数的完整签名是Double熵()const nost,而破坏它的是返回类型。该标准提供了熵的定义[7],但没有提供任何关于如何计算外部随机性来源的熵或不同情况下的预期返回值的指导。
这反过来又导致不同的实现各自做自己的事情。我们来看看微软的STL、libc++和libstdc++这三大巨头。
MS';的实现最好地处理了这一点。它知道它的RANDOM_DEVICE只是内核的加密安全随机的一个薄包装器,所以它总是返回32并将成员函数内联到头中以允许常量传播[8]。
按照实现的健壮性顺序,libc++紧随其后,因为它总是只返回0。此返回值不能反映实际情况,libc++';的Random_Device的5个可能配置[9]中有4个使用强随机后端,最后一个也提供强随机字节,除非用户故意破坏自己。返回值也使得libc+##的std::Random_Device::Effence的实现毫无用处,但至少它显然是无用的,所以没有给用户错误的希望和期望。这是有价值的。
std::Random_Device::熵最糟糕的实现可以在libstdc++中找到。之所以是最差的,是因为它不是明显没用的,你要想一想为什么返回值是没用的。这是因为与libc++不同,libstdc++可以返回非零值。在大多数配置中,libstdc++总是返回0[10],但是当它被配置为从/dev/urandom(或/dev/Random)读取时,它使用RNDGETENTCNT检查内核认为它有多少熵可用,并将其返回给用户。
这种方法的根本问题是TOCTOU。如果你首先检查是否有足够的随机性[11],然后才要求随机性,那么当你要求随机性的时候,它可能已经用完了,你再也得不到了。
在这一点上,我们知道我们可能必须实现我们自己的发行版,或者实现我们自己的Random_Device,或者检测我们正在针对哪个标准库进行编译,以及提供良好的Random_Device::Operator()实现的硬编码版本。但至少我们仍然可以使用标准库提供的所有不同的随机数引擎,对吗?
随机数引擎几乎正常工作。但是,如果某件东西几乎正常工作,那它就是坏了。
它用无符号整数值的随机数据播种特定版本的Mersenne Twister。假设sizeof(无符号整数)==4。mt19937的内部状态是2496(624*4)字节。总而言之,这意味着对于每个我们可以设定RNG种子的州,都有\(2^{4984}\)个我们不能设定RNG种子的状态。
某些输出值还唯一标识其种子。如果我告诉您代码程序打印了3046098682,那么您可以快速地[13]找到由RANDOM_DEVICE生成的种子,从而预测以这种方式播种的梅森龙卷风未来的所有输出[14]。
从理论上讲,该标准提供了一种适当地播种梅森龙卷风的方法。该工具名为SeedSequence,在标准库std::Seed_seq中有它的实现。再一次,当你试图在实践中使用它时,它又一次崩溃了。
Seed_seq本质上是std::Vector上的包装器,您可以赋予它一串随机性,然后随机数引擎可以提取(延伸的)随机性。它的用法如下:
这一次,我们用16(4*4)字节的随机性初始化了mt19937的实例。进步了!不过,此代码段有两个问题:
无法知道您必须向RandomNumberEngine T提供多少随机性,从而无法知道您必须向Seed_seq提供多少随机性。
Seed_seq由标准严格指定。标准强制的实现不是双向的[15]。
关于1.的一个有趣事实是,std::mersenne_twister_engine提供了一个成员变量,您可以查询它以确定它需要多少数据[16]。然而,这是标准化的意外,没有其他标准提供的随机数引擎提供检索此信息的方法。
第二个问题意味着,即使您硬编码了程序使用的所有随机数引擎类型的种子大小,您仍然不能使用std::Seed_seq进行初始化,因为它会丢失熵……。在Godbolt上有一个这样的例子:
#include<;array>;#include<;iostream>;#include<;Random>;int main(){std::Seed_seq seq1({0xf5e5b5c0,0xdcb8e4b1}),seq2({0xd34295df,0xba15c4d0});std:array<;uint32_t,2>。//打印1,因为Seed_seq::Generate不是双射std::cout<;<;(arr1==arr2)<;<;';\n';;}。
换句话说,即使您自己编写了满足SeedSequence命名要求的类型,也必须在某个地方硬编码随机数引擎类型的大小。
简而言之,使用C标准库生成随机数有很多问题,有些问题需要大量编程才能修复,有些则无法修复。如果由于某种原因,您只能使用C库,那么您绝对应该编写自己的C库。
使用C++标准库生成随机数可以解决使用C库的大部分问题。然而,这里的关键词是大多数,它反而引入了自己的问题。最后,您是否能成功使用<;Random>;取决于您的要求。
如果您需要跨平台的可重复性,那么您根本不能使用标准提供的发行版,您必须编写自己的发行版。
无论出于何种原因,如果您实际上需要随机数据,您要么必须编写自己版本的RANDOM_DEVICE,要么硬编码可以使用STD::RANDOM_DEVICE的平台+配置列表。
如果您想要正确地设定随机数引擎的种子,则必须编写您自己的SeedSequence,并硬编码所有随机数引擎所需的种子大小。
我的<;Random>;用例通常要求跨平台可重现性,需要适当的随机种子值,并且更喜欢完全种子的RNE。这意味着我要么必须自己编写90%的<;Random>;,要么使用不同的实现,如Boost.Random或PCG随机实用程序.。
而且我不是唯一一个。当我为修复<;Random>;编写几个标准化建议时,我在Reddit上做了一个非正式的民意调查,询问人们对<;Random>;的使用情况。绝大多数人要么回答他们有自己的实现,要么使用Boost.Random。很少有人使用其他开源库,而且非常、非常、非常少的人随机使用标准。
这就是这篇文章的内容。下一篇文章将探索修复<;Random>;的可能途径,使其在更多领域被更多人使用。
有两个问题。第一个是允许您的标准库从任意其他函数调用std::Rand。另一个是您的二进制文件中的其他库也被允许调用std::Rand,您无法在这样做之前告诉它们锁定一个互斥锁。↩︎。
这两种配置共享相同的libc,因此std::rand的结果将是相同的。然而,它与MSVC的结果明显不同,因为MSVC的std::Rand不能返回那么大的数字。↩︎。
微软的标准库实现实际上正在考虑更改为性能更好的std::uniform_int_Distribution实现。↩︎。
可重现的随机生成有许多不同的用例。模糊化、过程生成、联网客户端、物理模拟等。↩︎。
我相当肯定标准的库维护人员足够聪明,可以自己查找,但是\_(ツ)_/。↩︎。
这并不意味着您可以使用它进行编译时检查,但至少它是有意义的。↩︎。
Libc++可以使用get熵、arc4dom、nacl_secure_Random、rand_s,也可以从文件中读取,如/dev/urandom。理论上,用户可以指定自己的文件,从而获得非随机数据。↩︎。
例如,当前版本的libstdc++在Windows上使用rand_s。Rand_s是内核提供的加密安全随机数生成器,但是libstdc++仍然返回0。↩︎
我不同意这样的观点,即在内核正确初始化其池之后,我们可以用完内核的熵,但我可以看到如何实现一个真诚的实现。↩︎。
它实际上不能打印超过4字节无符号整数所有可能值的30%。↩︎。
用一个适当播种的梅森龙卷风,你必须观察624个连续的输出,才能预测所有未来产生的数字。↩︎。
如果您假设std::Seed_seq获得的随机数据永远不会多于随机数引擎稍后请求的随机数据,那么它就足以成为注入。这也不是注射。↩︎。
您实际上需要查询多个成员变量并执行一些算术运算,但是可以找出需要向std::mersenne_twister_engine提供多少随机数据才能完全初始化它。↩︎