铁锈并发:单一写入者原则
在我们全球独居的最后几天里,我偶然发现了“单身作家原则”(Single Writer Principle™)的概念,首先是通过一篇关于卡夫卡的文章,其中顺便提到了它,然后通过这篇优秀的文章放大了它,这是那种“我至少在过去三周里一直在找你,你一直藏在哪里?”有那么一刻。
因此,我不是一个真正的低级并发专家,我的重点相当于高级业务逻辑类型的设计,但我很惊讶,当您深入研究CPU缓存之类的低级方面时,您通常会发现,从高级角度看“有意义”的东西,往往也会从低级角度“做正确的事情”。
“单一编写者原则”就是这种工程意外发现的一个很好的例子。
有关较低级别的详细信息以及出色的高级描述,请访问https://mechanical-sympathy.blogspot.com/2011/09/single-writer-principle.html.。
在这里,我将在Rust中提供一个具体的例子,说明按照该原则实现的“微型系统”。我们还将了解这种设计如何使您的并发系统非常易于测试,以及阻塞和非阻塞工作流之间的区别。
我们将通过实现Kafka文章中描述的一半系统的并发版本来实现这一点,请参见下面的内容:
顺便说一句,我发现另一件令我惊讶的事情是,尽管它们存在差异,但从高级角度来看,分布式和并发系统看起来完全相同。因此,在卡夫卡的例子中,“消息传递”是通过卡夫卡实现的,这与横梁完全不同,但是您设计这些高级组件和工作流程的方式基本上是相同的。
不仅如此,人们可能会说,它们实际上只是处于不同规模的“相同事物”,因为分布式系统中“服务”的单个节点本身很可能是内部并发的,并且由各种并发“服务”组成。想一想这一点(这几天你没有其他事情要做)…
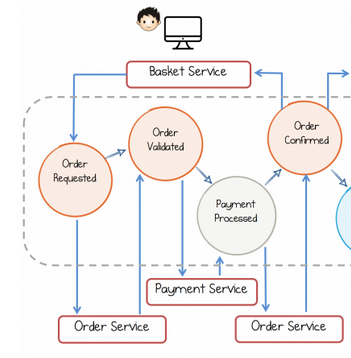
购物篮服务,它将请求订单,并等待由确认。
订单服务,处理来自购物篮服务的传入订单请求,验证它们,并将相关的付款请求发送到。
支付服务,验证支付请求,并使用订单服务确认它们,然后订单服务将向篮子服务确认订单。
我们将把整个事情包装在一个单元测试中,篮子服务只是由它的“主线程”表示。
稍后,我们还将添加“欺诈服务”,由支付服务使用,以调查阻塞和非阻塞工作流。
不幸的是,大多数在底层使用基于队列的实现,这打破了单一写入器原则,而Disruptor则努力分离关注点,以便在常见情况下可以保留单一写入器原则。
在这个例子中,我们将使用横梁中的通道,这是否违反了单一写入器原则?简单的回答是:我不知道。我认为实现是完全无锁的,但是我不太清楚这是否意味着它在一般情况下是完全没有编写者争用的,就像上面链接的Disruptor设计一样。
我确实知道,在任何情况下,我们仍然可以将所有“业务逻辑-Ky”状态保持在单个线程中,该线程运行事件循环并在本地状态上操作,以响应接收到的消息。因此,至少在这一部分,这给了我们“单一作家身份”。
首先,让我们看一下传递给服务的数据,我希望这些数据本身就说明了问题:
这在单元测试的主线程上运行,它基本上为四个不同的客户发送四个订单到订单服务,然后等待这些订单的确认并关闭。
请注意,他的服务拥有唯一的“客户-&>订单计数”地图。
此选项在两个频道上进行选择,一个频道来自购物篮服务,另一个频道来自未知的“支付”服务。
当它收到客户的新订单请求时,它会在“Order->;Customer”的映射中跟踪它,并向支付服务发送付款请求。
当它接收到来自支付服务的结果时,它向篮子服务确认订单。
并且当它从购物篮服务接收到“关闭”消息时,在已经向支付服务发送了类似的消息之后,它就关闭。
因此,请记住,本文是关于“单一写入器原则”的,如果我们退后一步看看这个迷你系统,我们会发现它似乎遵循了这个原则:每个服务唯一地拥有它运行自己(非常简单)业务逻辑所需的状态,当一个给定的服务需要“影响世界”另一个服务时,它通过发送消息来做到这一点。
例如,“确认订单”的不是“支付服务”,而是“订单服务”,以响应从“支付服务”收到的“支付确认”。
因此,以一种非常实用的方式,如果您想知道给定的“订单”发生了什么,您所需要做的就是在“订单服务”的选择处添加一个println,允许您检查消息流,包括新订单的请求和支付结果,这会影响“订单”的本地状态。
这些服务之间没有背压的概念,这意味着如果服务具有不同的运行时特征,则在它们的通信中使用的无限通道可能会被填满,有关处理这一问题的技术,请参阅上一篇文章。
另外,既然我们已经设置了所有这些代码,那么让我们来看一个阻塞工作流与非阻塞工作流的具体示例。
因此,让我们设想一下,我们的支付服务需要在客户下第一个订单时“检查欺诈”,但可以允许已经检查过的客户进行他们想要的所有额外交易(多么棒的欺诈检测算法)。
让我们设想一下,由于某些原因,这个“检查欺诈”操作相当昂贵,我们现在将以简单的“睡眠”为模型。
因此,让我们首先尝试将此操作添加到支付服务的工作流中:https://github.com/gterzian/single-writer/commit/753ca119042df779e99172a10185ee0c388a5fbf。
正如您所看到的,这个“检查欺诈”操作极大地降低了支付服务的整体吞吐量:当它执行检查时,它不能处理其他请求,甚至不能处理不需要它的订单。
因此,这里有一个机会:我们可以将这项业务转移到一个专门的“欺诈服务”中,与支付服务并行运行,允许支付服务全速处理“现有客户”,而欺诈服务则可以专注于为“新客户”开出昂贵的支票。因此,虽然这不会使登记本身更快,但“新客户”将不得不像以前一样等待很长时间才能看到订单得到确认,但是“现有客户”不会被队列中排在他们前面的“新客户”阻挡。
这是一个“拦截工作流程”的例子:当支付和诈骗服务并行运行时,支付服务会对诈骗检查的结果进行“拦截”。
结果是我们没有获得任何额外的吞吐量,这与我们在支付服务中运行欺诈检查操作时基本相同。
请注意,在某些情况下,从业务逻辑的角度来看,这样的阻塞工作流完全有意义。例如,如果我们有这样一条规则:如果我们收到某种类型的订单,我们必须丢弃所有东西,首先检查是否存在欺诈,并且在检查进行期间不处理任何其他订单。如果这种情况只是偶尔出现,那么将“欺诈服务”与“支付服务”并行运行甚至可能仍然是有意义的。
这一次,支付服务同时选择支付请求和新的“欺诈检查结果”通道,并且当订单需要欺诈检查时,该服务在一个本地州记录未决检查,将请求发送到欺诈服务,欺诈服务将并行执行该工作,并最终将结果发送回支付服务。
重要的是,当这样的检查正在进行时,支付服务可以继续处理其他订单。
正如我在上一篇文章中指出的,在使用异步/等待和任务时,阻塞和非阻塞的二分法同样重要。我们在这里使用线程,但是如果我们使用任务来建模各种服务,如果“支付服务”要“等待”欺诈检查,那么它也不能同时处理其他支付请求。
虽然运行任务的线程池上的线程不会被阻塞,但这不会帮助支付服务在欺诈检查进行期间处理其他请求。在当前的例子中,“阻塞线程”也不会阻塞它正在运行的内核,然而,操作系统可以在其上调度其他线程的事实并不能在处理支付请求时给我们带来更高的吞吐量。
因此,在这两种情况下,如果您想要高吞吐量,您需要自己通过使业务逻辑本身是非阻塞的方式来确保这一点。
如您所见,在最后一个示例中,我们仍然遵循前面概述的原则:支付服务只是拥有一段新数据,允许它“跟踪”未决的欺诈请求,并操作该数据段以响应从其他服务接收的消息。
另外,值得注意的是该系统的可测试性。当前示例基本上将整个过程作为集成测试运行,但是每个服务都可以单独测试,只需模拟其他服务,让测试使用它们的通道向服务发送消息(测试“输入”),然后断言该服务在各种通道上的输出对其他服务意味着什么。