构建您自己的“谷歌翻译”--高质量的机器翻译系统
在过去的几年里,机器翻译领域发生了一场革命。使用深度学习构建的新翻译系统已经取代了语言学家使用数十年的统计学研究构建的旧系统。流行的翻译产品,如谷歌翻译,已经改变了它们的内部结构,用新的深度学习模型取代了旧的代码。
这对每个人都很好。深度学习的方法不仅更准确,而且不需要你有语言学的研究生学位就能理解。从理论上讲,这很简单,任何有足够训练数据和计算机能力的人都应该能够建立自己的语言翻译系统。尽管如此,自己构建翻译系统仍然很困难,因为对于普通的卧室爱好者来说,所需的数据量和计算能力是令人望而却步的。
但就像机器学习中的其他一切一样,机器翻译正在迅速成熟。工具越来越容易使用,GPU变得越来越强大,培训数据也比以往任何时候都更加丰富。现在,您可以使用现成的硬件和软件构建语言翻译系统,该系统足够好,可以在实际项目中使用。最棒的是,你不需要向谷歌支付任何API费用就可以使用它。
那我们就开始吧!让我们构建一个西班牙语到英语的翻译系统,它可以高精度地翻译“来自野外”的文本!
我们翻译系统的核心将是一个神经网络,它接收一个句子,并输出该句子的翻译结果。我以前写过机器翻译系统的历史,以及我们如何使用神经网络翻译文本,但这里是简短的版本:
神经翻译系统实际上是两个端到端相互连接的神经网络。第一神经网络学习将单词(即句子)序列编码成表示其含义的数字阵列。第二个神经网络学习将这些数字解码成意思相同的单词序列。诀窍是编码器接受一种语言的单词,而解码器输出另一种语言的单词。因此,实际上,该模型通过中间数字编码学习从一种人类语言到另一种人类语言的映射:
为了对句子的意思进行编码和解码,我们将使用一种特殊类型的神经网络,称为递归神经网络。标准的神经网络没有记忆。如果您给它相同的输入,它每次都会得到相同的结果。相反,递归神经网络之所以称为递归,是因为上一次输入会影响下一次预测。
这很有用,因为句子中的每个单词都不是单独存在的。每个词的意思取决于它在句子中的上下文。通过让句子中的每个词影响下一个词的值,它允许我们捕捉到一些上下文。
因此,如果你向神经网络显示单词“my”、“name”、“is”,然后要求它对单词“Adam”的含义进行编码,它将使用前面的单词“知道”来表示单词“Adam”作为一个名称的含义。如果您想了解更多有关其工作原理的详细信息,请查看我之前的文章。
如果你精通机器学习,一提到递归神经网络,你可能会打哈欠。如果是这样,请跳到下面的Linux shell命令,开始训练您的模型。我明白,机器学习是一个快速发展的领域,几年前还是绝对革命性的东西现在已经是古老的新闻了。
事实上,还有一种更新的语言翻译方法,它使用一种名为Transformer的新型模型。转换器模型进一步尝试通过对每个单词之间的交叉关系建模来捕捉句子中每个单词的上下文含义,而不是仅仅考虑单词的顺序。我也写过关于变形金刚模型的文章,但是我们将在这个项目中使用递归神经网络来保持训练时间的合理性。别担心,成绩还是会很好的!
很好,那么我们将使用两个递归神经网络来翻译文本。我们将训练第一个人用西班牙语编码句子,训练第二个人把它们解码成英语。如果你相信我的Reddit评论,每个拥有Python副本的高中生都已经知道如何创建递归神经网络,所以是时候开始了,对吗?
还没那么快!。我们需要一种策略来处理杂乱无章的真实数据。人类非常善于在没有任何帮助的情况下从混乱的数据中提取信息。例如,你可以毫无问题地读到这句话:
对格式完美的文本进行训练的神经网络不会知道这是什么意思。神经网络没有能力推断出它们在训练数据中看到的东西。如果神经网络以前从未见过世界上的“计算机”,它不会自动知道它与“计算机”的含义相同。
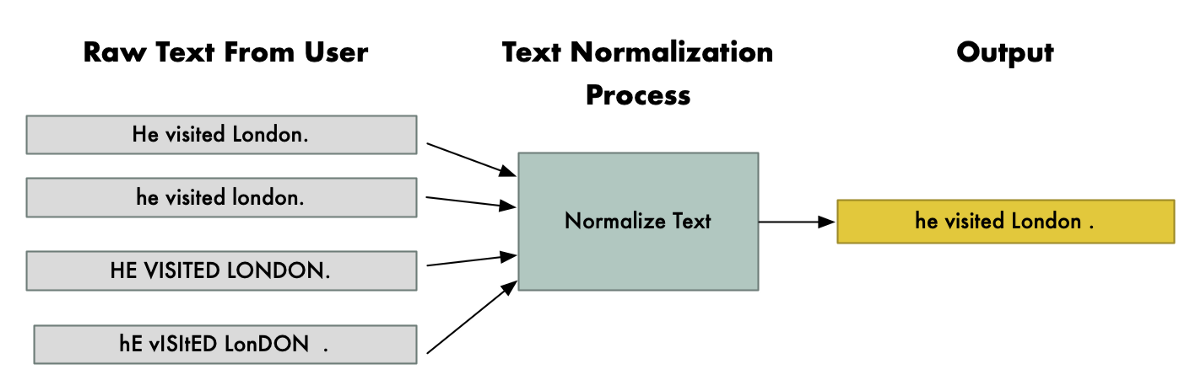
解决方案是将文本标准化-我们希望尽可能多地删除格式差异。我们将确保单词在相同的上下文中总是以相同的方式大写,我们将修复标点符号周围的任何奇怪的格式,我们将清理MS Word随机添加的任何奇怪的卷曲引号,等等。整个想法是确保相同的句子总是以完全相同的方式输入,无论用户如何键入。
请注意,无论用户的Shift键工作得多么糟糕,“他访问了伦敦”这句话是如何以同样的方式规范化的。注意,London总是大写,而其他单词不大写,因为它通常用作专有名词。确保文本格式清晰,这将使神经网络的工作变得容易得多。
下面是我们的整个翻译管道的外观,说明我们要翻译的文本,并以翻译的版本结束:
首先,我们需要把课文分成几个句子。我们的神经网络一次只能翻译一个句子,如果我们试图一次输入整个段落,结果会很差。
将文本拆分成句子似乎很容易,但实际上这是一项棘手的任务,因为人们可能会以各种不同的方式嵌套标点符号和格式。对于这个项目,我们将使用一个用Python编写的简单句子拆分器来减少您需要安装的第三方库的数量。但是NLP库(如Spacy)包括复杂的句子拆分模型,如果这不能满足您的需要,您可以使用这些模型。
接下来,我们将执行文本规范化。这是最难做好的部分,如果你在这一步上偷工减料,最终的结果将会令人失望。一旦我们有了规范化的文本,我们就会把它提供给翻译模型。
请记住,您还需要颠倒文本规范化和句子拆分步骤来生成最终翻译。所以我们有一个反规范化的步骤,然后一个将文本重新组合成句子的步骤。
我们将使用Python3编写粘合代码来规范化文本、执行转换并输出结果。
您可能会认为我们会使用TensorFlow或PyTorch这样的通用机器学习框架来实现我们的翻译模型。取而代之的是,我们将使用Marian NMT,这是一个专门为机器翻译设计的基于C++的机器学习框架,主要由微软翻译团队开发。它已经内置了几个神经翻译模型架构。
TensorFlow和PyTorch非常适合实验和尝试新的神经网络设计。但是,一旦您弄清楚了模型体系结构,并且您正在尝试扩展您的设计来处理现实世界的用户,您就不再需要通用工具了。
Marian NMT是一个专门的工具,旨在方便快捷地构建生产级翻译系统。这里没有必要重新发明轮子。这是一个例子,说明了随着机器学习从研究实验室进入日常使用,软件是如何变得更加成熟的。
要运行Marian,我们需要一台运行Linux的计算机。任何功能相当强大的计算机都应该可以工作。我用的是一台台式电脑,Ubuntu Linux18.04,英特尔i7CPU,内存32 GB。为了存储训练数据,我使用的是普通固态硬盘。
重要的是,这台电脑有一个很好的NVIDIA GPU,有足够的显存。GPU承担着大部分的计算工作,所以这是你应该投资的地方。我使用的是一台内存为24 GB的英伟达泰坦RTX。至少,你需要一个显存至少为8 GB的GPU。其他不错的消费级GPU选择包括GTX 1080 Ti或GTX 2080 Ti。像NVIDIA Tesla或Quadro系列这样的服务器级图形处理器也可以使用。
您可以将Marian与单个GPU或多个GPU并行使用以加快速度,但每个GPU都需要有足够的内存来单独保存模型和训练数据。换句话说,两个内存为4 GB的GPU无法取代一个内存为8 GB的GPU。
尽管有微软的支持,但玛丽安还没有在Windows上运行。Mac OS也不受支持。所以,只管咬紧牙关,要么在你的计算机上安装Linux,要么考虑从你最喜欢的云提供商那里租用一台云中的Linux机器。
我推荐为这个项目安装Ubuntu Linux18.04LTS。尽管最近发布了Ubuntu Linux20.04LTS,但更新GPU驱动程序和深度学习库以适应新的Ubuntu版本需要时间。不要尝试使用最新版本的Ubuntu,除非您愿意处理额外的麻烦并解决您自己的安装问题。
NVIDIA的CUDA和cuDNN库使Marian能够利用您的GPU加速培训过程。因此,在我们继续之前,如果您尚未安装CUDA和cuDNN,则需要安装它们。
在Ubuntu Linux 18.04上,我建议安装CUDA/cuDNN版本10.1。这些版本会很适合玛丽安。
如果您安装了不同的版本,则必须调整下面的命令以与之匹配。NVIDIA臭名昭著,因为在新版本的CUDA中稍作改动会导致与旧软件的不兼容,所以如果您偏离了标准路径,请再次准备好进行您自己的调试。
在编译Marian之前,您需要安装比Ubuntu18.04默认包含的更新版本的CMake。您还需要安装一些其他必备组件。
不过,别担心,没什么大不了的。只需运行以下终端命令:
#通过第三方repo安装较新的CMake wget-O-https://apt.kitware.com/keys/kitware-archive-latest.asc 2>;/dev/NULL|sudo apt-key add-sudo apt-add-pository';deb https://apt.kitware.com/ubuntu/bionic Main-Get install cmake git build-Essential libBoost-all-dev。
请注意,这些命令从第三方软件包存储库中提取软件包。因此,请检查命令正在执行的操作,以确保您对此没有问题。
安装了这些必备组件后,运行以下命令下载并编译Marian(包括示例和帮助器工具,它们分布在不同的git repos中):
#下载并编译MARIAN CD~GIT CLONE https://github.com/marian-nmt/marian CD MARIAN MKDIR BUILD CD BUILD CMAKE-DCOMPILE_SERVER=ON-DCUDA_TOOLKIT_ROOT_DIR=/USR/LOCAL/CUDA10.1/.。Make-J4#抓取并编译Marian模型示例和辅助工具CD~/Marian/git clone https://github.com/marian-nmt/marian-examples.git CD Marian-Examples/CD Tools/Make。
最后,我与Marian分享了我们将用来训练从西班牙语到英语的模型的脚本。它们基于Marian附带的罗马尼亚语翻译示例,但针对西班牙语到英语进行了修改,并扩展到更大的数据集。让我们抓住这些:
#下载本文的西班牙语到英语脚本cd~/marian/marian-examples git克隆https://github.com/ageitgey/spanish-to-english-translation#安装我们将使用的稍后cd西班牙语到英语翻译的模块sudo python3-m pip install-r requirements.txt。
您可以随意调整这些脚本,使其适用于您想要翻译的任何语言对。以拉丁语为基础的语言,如法语或意大利语,需要很少的修改,而不太相似的语言,如普通话,则需要更多的工作。
为了训练一个翻译模型,我们需要数百万对完全相同的句子,只是它们已经被翻译成两种语言。这称为平行语料库:
我们有的句子对越多,我们的模型就越能更好地学习如何翻译不同类型的文本。要创建一个工业实力模型,我们需要数千万个或更多的训练句子。最重要的是,这些句子需要涵盖人类表达的整个范围,从正式文件到俚语和笑话。
一个糟糕的翻译系统和像谷歌翻译一样强大的翻译系统之间最大的区别是训练数据的数量和种类!幸运的是,在2020年,我们可以在很多地方找到意外创建的并行数据,并可以通过一些巧妙的技巧将其转化为训练句对。
对于正式和法律文本,我们有欧盟的礼物。他们将法律文件翻译成成员国的所有语言,包括英语和西班牙语。沿着同样的思路,我们可以找到其他国际机构的交叉翻译的法律文本,如联合国和欧洲中央银行。
对于历史写作,我们可以从翻译成不同语言的经典书籍中寻找句子对。我们可以选择版权过期的书籍,将这些作品的不同译本配对,以创建我们知道的表达相同事情的成对句子。
对于非正式的交谈,我们有DVD的礼物。自20世纪90年代末DVD格式推出以来,几乎所有的电影和电视节目都包含了几种语言的机器可读字幕。我们可以将相同电影和电视节目的不同译本配对,以创建并行数据。同样的想法也适用于有字幕的较新内容,如蓝光和YouTube视频。
现在我们知道在哪里可以找到数据,但要清理和准备这些数据仍然有很多工作要做。幸运的是,OPUS(开放平行语料库)上令人惊叹的人们已经完成了收集多种语言的句子对的工作。你可以在他们的网站上浏览和下载他们所有的平行句子数据。这将极大地加速我们的项目,因此请务必查看本文末尾对他们工作的引用。
我们稍后运行的训练脚本将自动从OPUS下载这些数据源,为我们提供近8500万个零工作的翻译句子对。太棒了!
OPUS按语言对提供文件。因此,如果您想创建芬兰语到意大利语的翻译模型,而不是西班牙语到英语,您可以通过下载该语言对的文件来实现。请记住,对于使用较少的语言来说,很难找到句子对。另外,请记住,有些语言需要独特的文本规范化方法,而本例中没有涉及这些方法。
还要记住,这些数据来自不同的地方,质量各不相同。在这些下载中肯定会有一些坏的或重复的数据。当您处理庞大的数据集时,数据质量永远得不到保证,而且您经常需要亲自动手来查找和修复任何明显的问题。
我包含的用于训练模型的脚本将自动下载并为您准备数据,但是如果您想要为不同的语言对构建翻译模型,那么有必要讨论一下涉及的步骤。
我们从OPUS下载的每个数据源将包括两个文本文件。一个文本文件具有英语句子列表,而另一个文本文件以相同的顺序具有匹配的西班牙语句子列表。因此,我们将得到大量的文本文件,如下所示:
合并:将所有英文文本文件合并为一个庞大的文本文件。同样,合并所有西班牙语文本文件,确保所有句子保持有序,以便英语和西班牙语文件仍然匹配。
随机排列:随机排列每个文件中的句子顺序,同时保持英语和西班牙语文件中句子的相对顺序相同。混合来自不同来源的训练数据将有助于模型学习跨不同类型的文本进行泛化,而不是首先学习转换正式数据,然后学习转换非正式数据,等等。
拆分:将每种语言的主数据文件拆分为培训、开发和测试部分。我们将在大量训练数据上训练模型,但保留一些句子用于测试模型并确保其工作。这确保了我们使用它在训练期间从未见过的句子来测试模型,因此我们可以确定它不只是记住了正确的答案。
永远不可能获得涵盖每一个可能的单词的训练数据,因为人们总是在编造新词。为了帮助我们的翻译系统处理从未见过的单词,我们将使用一种称为子词切分的方法。
子词切分是将单词分成更小的片段,并教导模型在每个单词的每个片段之间进行翻译。人们希望,如果模型看到一个它以前从未见过的单词,它至少可以尝试通过翻译组成这个单词的子词来猜测该单词的意思。
假设我们的训练数据包含单词Low、Low、Newer和Wide。我们可以把单词分成词根和后缀:
现在想象一下,我们被要求翻译最宽这个词。尽管该词从未出现在训练数据中,但模型将知道如何翻译WID和EST,因此通过将这两个子词翻译放在一起,它将能够很好地猜测最宽的意思。这不会总是完美的,但它在很多情况下都会工作得足够好,而且它会使翻译模型总体上更准确。
我们将使用的子字分割的具体实现称为BPE,即字节对编码。你可以在最初的研究论文中读到它是如何工作的。
要利用BPE,我们需要训练一个新的BPE模型来适应我们的训练数据集,然后我们将在文本规范化过程中包括一个额外的步骤,我们在该BPE模型中运行文本。同样,我们需要在反规范化过程中添加步骤,以重新连接最终翻译中被BPE模型拆分成单独单词的任何单词。
下载培训数据、准备数据、创建BPE模型以及使用Marian培训实际翻译模型的整个过程都在一个脚本中。要启动所有操作,请运行以下命令:
您可以查看run-me.sh脚本,了解每一步都发生了什么。它非常简单-它下载训练数据,合并它,将其正常化,然后启动Marian训练过程。
如果您要构建生产级翻译系统,请随意将此脚本替换为您自己的实现。此脚本只是您需要执行的步骤的指南。
在准备好数据并开始训练模型之后,您将看到如下所示的输出:
[2020-05-01 10:09:23]EP.。1:向上。1000:参议员154,871:费用70.37619781:时间370.45秒:5024.86字/秒。
这条消息说,我们目前处于第一个纪元(第一次通过训练数据),到目前为止,模型已经更新了1000次,处理了154,871个句子对。
70.3的成本值告诉您模型培训过程在找到最佳解决方案方面已经走了多远。成本为0.0将意味着模型是完美的,并且总是将训练数据中的任何西班牙语句子转换为完美匹配的英语翻译。这永远不会发生,因为。
..



