标准库的快捷方式
我们最近决定大幅扩展Dark的标准库。虽然我们的标准库为Dark“框架”提供了很多功能,包括HTTP、Worker/Queue和数据存储函数,但我们在“包含电池”语言中所期望的常规函数(如用于数学和操作标准数据类型(如列表、字典、数字和字符串)的函数)上略显不足。
作为更快发货的捷径,我们决定从榆树标准库开始。ELM的标准库设计得很好,在可用性方面有很大的考虑。Dark和Elm都是为相似的受众设计的:第一次使用函数式语言的前端开发人员。黑暗和榆树的语言有许多共同之处,黑暗受到榆树和其他类似语言(如OCaml)的影响。真的,榆树有一个完美的标准库,可以从中获取灵感!
这也不是我们第一次使用榆树标准库:Dark是第一年用榆树编写的,我们使用榆树的标准库来影响我们的桌布OCaml标准库。
考虑到这些相似之处和我们之前的经验,使用榆树的库来扩展Dark的标准库似乎微不足道。然而,Elm和Dark之间的细微语义差异导致了在实践中如何工作的重大微妙之处。
在许多情况下,我们需要实现与我们正在查看的ELM函数不同的行为或函数签名。所有这些都可以归结为细微的语言差异。
ELM支持将流水线作为一流的语言功能。例如,在Elm中,您可以编写:
大多数ELM函数都设计为允许简单的流水线操作:您正在操作的主值排在最后。Paul花了大量时间编写Clojure,它使用了流水线,但没有严格遵守这一原则,这也是使Elm成为一件令人愉快的事情的原因之一。
虽然Dark也是为流水线设计的,但我们改为通过管道进入第一个位置。因为我们通过管道进入第一个位置,所以显然需要更改参数顺序才能获得相同的效果。
但它走得更远了一点。ELM的函数名称通常会考虑参数顺序。例如,在以下情况中,ELM使用后缀“by”、“base”和“with”,指的是第一个参数。
List.map(ReainderBy 4)[-5,-4,-3,-2,-1,0,1,2,3,4]--[-1,0,-3,-2,-1,-1,0,1,2,3,0]logBase 10 100==2 logBase 2 256=8排序带有flippedCompison[1,2,3,4,5]==[5,4,3,2,1]flippedcompison a b=案例比较LT-&G。
对于Dark的版本,我们最终使用List::sortByCompator而不是List.sortWith,使用Int::Remainer作为RemainerBy,以便将命名与不同管道行为所需的参数顺序相匹配。我们忘了添加日志函数,但我们可能已经将其命名为Int::log。
ELM在全局名称空间中添加了许多数学函数,包括abs和pi。使用较小的可识别的数学名称可以让您比写出的表达式更快、更有效地理解复杂的表达式,因此这些短名称通常是有意义的。然而,当我们权衡“黑暗”的设计目标时,它开始看起来截然不同。
黑暗开发者正在同时学习黑暗语言和黑暗编辑器。因此,我们在很大程度上依赖于自动完成来使标准库可被发现。将所有函数放在模块名称空间中便于发现函数,因此将这些函数放入Math名称空间或相关的名称空间(如Int或Float)是有意义的。
榆树有一个数字类型类,这是黑暗还没有的,这意味着在榆树中,abs可以同时使用整数和浮点数。将这些函数放在模块中允许我们根据类型进行区分:我们有Int::AbsoluteValue和Float::AbsoluteValue。
最后,我们决定不使用短函数名。我们认为Dark通常不用于复杂的数学表达式,因此缩短函数名没有多大价值。数学表达式在前端更为常见,Elm就是为此而设计的。
我们确实有计划通过提供对编辑器如何显示名称的控制来支持短名称,或者通过在自动完成中为不同的名称赋予别名来增加函数可发现性,但是我们还没有充实这些想法。
标准库需要管理安全性和易用性之间的微妙界限。榆树必须走这条线,并不是所有的功能都落在这条线的一边。例如,Elm的String.uncons返回笨重的可能(char,string)。同时,当列表具有不同的长度时,List.map2会静默地从较长的列表中删除元素。
Dark试图在可能的情况下既支持安全性又支持易用性。我们构建了一个名为“Error Rail”的功能,它可以自动展开选项和结果,使它们更易于在编码的早期探索性阶段使用,此时快速而简单地编写代码比处理所有可能情况更重要。稍后,当程序员希望确保他们的代码在每种特殊情况下都能正常工作时,他们可以“将函数从错误轨道上移除”来处理边缘情况。
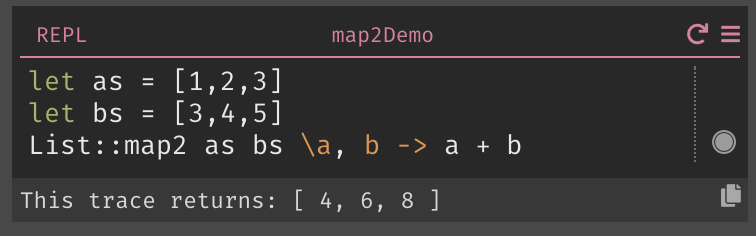
这会影响Dark‘s List::Map2的设计。此函数接受两个列表,并对两个列表中相同位置的参数调用函数。当清单的长度不同时,我们是否应该:
通过让它正常工作来选择易用性(通过不安全地忽略较长列表中的额外元素,就像Elm所做的那样)?
或者选择确保程序员知道列表何时不同长度的安全性(代价是将返回值包装在程序员必须处理的选项中,这类似于OCaml Core所做的事情)?
由于存在错误轨道,实现list::map2以返回选项使得列表长度相等的常见情况变得容易:
如果作者知道列表的长度永远不会不同,那么它们就可以到此为止。或者,他们可以将该功能从轨道上移除以处理选项:
如果他们想要从较长的列表中删除元素的行为,他们可以改用我们新的list::map2Shortest(当编码器使用map2时,自动完成将显示这两个选项,因此这是可发现的):
关于浮点也有类似的问题。Dark中的一个目标是不使用NaN(NaN是浮点值,当您使用不确定的结果(如0.0/0.0)执行浮点数学时会显示该浮点值)。既然Dark已经对结果类型进行了结构化的错误处理,为什么还要通过NAN支持隐式错误呢?
不过,ELM确实有NAN,所以当我们设计浮点函数时,它们在NAN的情况下都有不同的行为,它们也有不同的签名(返回结果而不是普通浮点)。
所以我们选择了安全性,并允许Error Rail提供易用性,对吗?可惜不是。不幸的是,我们发现我们还不支持运算符的错误轨道,这使得将结果用于算术变得困难。此外,错误轨道在其当前表现形式中实际上是为了使原型更容易,但是如果不从轨道上提取值,您就不能实际处理错误。这使得将其用于诸如算术之类的事情变得很麻烦。唉,我们不得不暂时搁置这件事。
我们不相信我们在这一轮的标准库中都做对了。幸运的是,我们将Dark设计为易于更改,并且我们添加的每个函数都是单独版本的。这允许我们稍后创建新版本的函数,使用Dark的开发人员可以单独选择升级。
在项目过程中,我们添加了61个函数,在某些情况下不建议使用旧的、命名不佳的函数。现在,我们总共在Bool、Float、Int、Math、Dict、List、Option、Result和String模块中有125个“基本”函数(这不包括HTTP、DB和其他Dark框架模块)。
在这125个函数中,我们最终使用ELM中的不同函数名称的有44个,参数顺序不同的有30个,行为不同的至少有10个。
榆树有一个很棒的标准库,它是扩展黑暗的一个很好的起点。语言语义和目标的细微之处对标准库有很大影响,因此我们发现我们需要很好地理解Elm和Dark之间的差异。